-
Recurse Center - Batch 3 - Cycle 20250305-20253207 - Debugging
Date: 2025-03-07
Category: rc
-
Recurse Center - Batch 3 - Cycle 20250205-20250207 - Training
Date: 2025-02-07
Category: rc
-
Recurse Center - Batch 3 - Cycle 20250128-20250130 - Processing
Date: 2025-01-30
Category: rc
-
Recurse Center - Batch 3 - Cycle 2025012-20250114 - Decoding
Date: 2025-01-26
Category: rc
-
Recurse Center - Batch 3 - Cycle 2025012-20250114 - Encoding
Date: 2025-01-22
Category: rc
-
Recurse Center - Batch 3 - Cycle 2025012-20250114 - Stagnation
Date: 2025-01-14
Category: rc
- Research
- Research
-
Introduction exercises in vim from Primagen's Vim As Your Editor series.
-
I outlined the different steps necessary for implementing the speech transformer's forward pass:
- And I implemented the Attention layer, based on some past work / resources from ARENA:
-
Recurse Center - Batch 3 - Cycle 20250108-20250110 - Extension
Date: 2025-01-10
Category: rc
-
Connect Zora to LLM
-
Create browser extension / native desktop apps for Zora
-
Integrate with Home Assistant
-
TCP/IP Illustrated (with Rust?)
-
Operating Systems: Three Easy Pieces (on Heap?)
-
Inside the Machine (on Heap?)
-
Gang of Four Design Patterns (for Zora?)
-
SICP
-
Python Elements of Programming Interview (for software engineering/computer science?)
-
Learning Clojure (for fun / stretching my brain / doing something completely orthogonal to everything else I'm working on)
-
Recurse Center - Batch 2 - Cycle 20241211-20241213 - Conclusion
Date: 2024-12-13
Category: rc
-
Recurse Center - Batch 2 - Cycle 20241207-20241209 - Conversation
Date: 2024-12-09
Category: rc
-
Recurse Center - Batch 2 - Cycle 20241203-20241205 - Dimension
Date: 2024-12-05
Category: rc
-
Recurse Center - Batch 2 - Cycle 20241129-20241201 - Extension
Date: 2024-12-01
Category: rc
- Extend my RC batch an additional six weeks
- Work on Audrey and feature visualizaiton examples for a presentation at RC at the end of my batch
- Continue working on Heap
- Continue chipping away at speech transformer and mech interp, knowning that I'll get to more of it during my (hopefully approved) batch extension
-
Recurse Center - Batch 2 - Cycle 20241125-20241127 - Transportation
Date: 2024-11-27
Category: rc
-
Recurse Center - Batch 2 - Cycle 20241117-20241119 - Gestation
Date: 2024-11-19
Category: rc
-
Recurse Center - Batch 2 - Cycle 20241113-20241115 - Continuation
Date: 2024-11-15
Category: rc
-
Recurse Center - Batch 2 - Cycle 20241109-20241111 - Vacation!
Date: 2024-11-11
Category: rc
-
Recurse Center - Batch 2 - Cycle 20241105-20241107 - Reflection
Date: 2024-11-07
Category: rc
-
Today I worked on organizing the first Heap Computer Club meeting.
-
Afterawrd I shared my demo video of Audrey to Recursers, and I've been getting some great responses. Here's the video below:
- Finally I spent some time thinking about this ASR library that I want to make.
-
I had some more tasks to do with Heap, including cleaning up some unused disk space and figure out our meeting time.
-
I also had a wonderful chat with a faculty member at Recurse, who helped me unpack my thoughts about the self-directives above, as well as helped me articulate outloud my why and decide to make this library.
-
I also did some retraining on Audrey, cleaning up some code and using a larger (generated) dataset.
-
I went to an AI Safety presentation by a fellow Recurser that helped oe appreciate more some of the implications of rapid AI progress and why AI safety is important.
-
I did some research on feature visualization in CNNs
-
I wrote the README for Zora!
-
Recurse Center - Batch 2 - Cycle 20241101-20241103 - Direction
Date: 2024-11-03
Category: rc
-
Recurse Center - Batch 2 - Cycle 20241028-20241030 - Transition
Date: 2024-10-30
Category: rc
-
Recurse Center - Batch 2 - Cycle 20241024-20241026 - Interpretation
Date: 2024-10-26
Category: rc
-
Open Problems in Mechanistic Interpretability: A Whirlwind Tour | Neel Nanda | EAGxVirtual 2023
-
Open Problems in Mechanistic Interpretability: A Whirlwind Tour
-
Concrete Open Problems in Mechanistic Interpretability: Neel Nanda at SERI MATS
-
Record my own voice for digits
-
Clean up my notebook code :)
-
Train a few more times and write up to Weights and Biases
-
Look into how I can introduce ideas of observability into this model
-
Conformer: Convolution-augmented Transformer for Speech Recognition
-
Conformer: Convolution-augmented Transformer for Speech Recognition
-
PyTorch implementation of Conformer: Convolution-augmented Transformer for Speech Recognition
-
Recurse Center - Batch 2 - Cycle 20241020-20241022 - Transformation
Date: 2024-10-22
Category: rc
-
Recurse Center - Batch 2 - Cycle 20241016-20241018 - Optimization, Propagation, Variation, Generation, Discrimination
Date: 2024-10-18
Category: rc
-
This page, A Visual Explanation of Gradient Descent Methods (Momentum, AdaGrad, RMSProp, Adam), gave a lot of lovely visual examples of how these optimizers work and how each of them improves over the previous one.
-
This video on Optimization for Deep Learning (Momentum, RMSprop, AdaGrad, Adam) also looked good as well.
-
How to use Weights and Biases to do a sweep of hyperparamters to search for the most optimal hyperparamters that maximize model accuracy.
- Today I was mostly off-line tending to non-Recurse related things.
-
Concrete Steps to Get Started in Transformer Mechanistic Interpretability
-
Progress measures for grokking via mechanistic interpretability
-
Accompanying website to Progress Measures for Grokking via Mechanistic Interpretability
-
Mechanistic Interpretability - NEEL NANDA (DeepMind) on Machine Learning Street Talk
-
Reading AI's Mind - Mechanistic Interpretability Explained [Anthropic Research]
-
Recurse Center - Batch 2 - Cycle 20241012-20241014 - Normalization
Date: 2024-10-14
Category: rc
-
Start NNFS Chapter 7
-
Finishing up Ch 0 of ARENA next cycle
-
Starting Chapter 1 in two sycles
-
I want to carve out time next cycle to work on simple sound MNIST project:
-
Here are some thoughts:
-
speech digit recognizer (Audrey)
-
generating synthetic sound digit dataset
-
training like mnist or using resnet
-
visualizing dataset
-
visualizing network
-
introducing data augmentation for:
-
musicality
-
repetition
-
stress
-
prosody etc.
-
-
Demo: Making a phone call / sending a text
-
-
-
Look into CUDA
-
Recurse Center - Batch 2 - Cycle 20241008-202410010 - Convolution
Date: 2024-10-10
Category: rc
-
Finish Chapter 0 in ARENA
-
Finish Chapters 7, 8, and 9 in NNFS
-
Update my ml_ai_self_study repo on Github
-
Work on my ASR system on Heap with transformers :)
-
Think about creating a synthetic speech dataset for numbers 0-9...
-
https://github.com/Jakobovski/free-spoken-digit-dataset
-
https://adhishthite.github.io/sound-mnist/
-
-
Recurse Center - Batch 2 - Cycle 20241004-20241006 - Transposition
Date: 2024-10-06
Category: rc
-
Review PyTorch methods (do the 100 NumPy exercises in PyTorch)
-
Update my ml_ai_self_study repo on Github
-
Continue working through the ARENA pre-requisites (last week of pre-requisites!)
-
Finish up to Chapter 6 in NNFS
-
Attempt to create an ASR system on Heap with transformers :)
-
Recurse Center - Batch 2 - Cycle 20240930-20241002 - Submersion
Date: 2024-10-02
Category: rc
-
Load all of the paper's from Ilya's list into Zotero and download locally.
-
Continue working through the ARENA pre-requisites.
-
Start working on Neural Networks from Scratch, reading the book and watching the videos.
-
Work through 100 NumPy exercises.
-
Consider what I now know about matricies and transformations to solve leetcode problems like rotate array and rotate image.
-
Do a bit more syling and implement creature comforts on this blog.
-
Recurse Center - Batch 2 - Cycle 20240926-20240928 - Attenuation
Date: 2024-09-28
Category: rc
-
I worked on some Leetcode problems, which I haven't touched in...years?
-
I also researched some guides to get back into DS+A studying. Here are some resources for moving forward into the future:
-
Did more DS+A, with new Recurse friend Camille Rullan.
-
Read through at a high level the Week 0: Prerequisites
-
Watch and take notes on 3Blue1Brown - Essence of Linear Algebra videos
-
Work through Changlin's Basic Linear Algerbra exercises.
-
Get my env set up on Heap
-
Matrices
Date: 2024-09-28
Category: dsa
- Key insight: Find the 0 in our matrix and store the location in a list. Once we've gone through our matrix, go back to our list and set its entire row and column to zero. I went with a naive, space inefficient approach for now, but will keep thinking about how to do this in O(m+n) and eventually constant space...
-
Stacks
Date: 2024-09-27
Category: dsa
- Key insight: Pop elements from stack 1 over to stack 1, pop the top of stack 2 to get our queue pop behavior, then bring everything from stack 2 back to stack 1.
-
Arrays
Date: 2024-09-26
Category: dsa
- Key insight: Figure out the complement for each value in nums, and then store that complement in a dictionary, wit the index of that value. After, iterate through nums again and see if n is in our complement_index dict (which means we found a complement). If so, return our current index of the complement, plus the index of the original value from our first scan. Make sure that both of these indexes aren't the same value.
-
Strings
Date: 2024-09-26
Category: dsa
- Key insight: When working with palindromes, look for a way to track pairs, and one odd character. For this problem, we leverage the notion that valid palindrome has pairs of characters, and at most one non-pair. We use a set to find pairs and if we have one, add two to our counter. At the end, if we have any more characters in our set, just add 1 to our counter. I wasn't sure how leetcode wanted to handle a string that couldn't make a palindrome, but I guess returning 0 makes sense in this context.
-
Recurse Center - Batch 2 - Cycle 20240922-20240924 - Reunion
Date: 2024-09-24
Category: rc
-
A Cycle of Study, Make, Play
Date: 2024-07-31
Category: process
-
Flights of Fancy
Date: 2020-05-26
Category: research
-
Recurse Center - Batch 1 - Week 12 - Offset
Date: 2020-03-27
Category: rc
-
Recurse Center - Batch 1 - Week 11 - Buffer
Date: 2020-03-20
Category: rc
-
Recurse Center - Batch 1 - Week 10 - Parabolic
Date: 2020-03-13
Category: rc
-
Recurse Center - Batch 1 - Week 9 - Unsounding
Date: 2020-03-06
Category: rc
-
Recurse Center - Batch 1 - Week 8 - Inflection Point
Date: 2020-02-28
Category: rc
-
Recurse Center - Batch 1 - Week 7 - Cycle
Date: 2020-02-21
Category: rc
-
Recurse Center - Batch 1 - Week 6 - Midpoint
Date: 2020-02-14
Category: rc
-
Recurse Center - Batch 1 - Week 5 - A Local Maxima
Date: 2020-02-07
Category: rc
-
Recurse Center - Batch 1 - Week 4 - Chirps
Date: 2020-01-31
Category: rc
-
Recurse Center - Batch 1 - Week 3 - Two Sides of the Same Coin
Date: 2020-01-24
Category: rc
-
Recurse Center - Batch 1 - Week 2 - Noise to Signal
Date: 2020-01-17
Category: rc
- ML Signal Processing
- Neural audio synthesis
- The MARL community out of NYU (Brian McFee, Juan Pablo, Keunwoo Choi)
- The Music Hackathon community
-
Recurse Center - Batch 1 - Week 1 - Hello, RC!
Date: 2020-01-10
Category: rc
- NCA / Newtown Creek Bird Classifier
- Freesound multilabel classifier
- Shubert's tone generator
- Voice recognition for security
- Sonic generator with GANs
-
Quiet Music, Weak Sounds
Date: 2017-06-01
Category: residencies
Debugging
This cycle was spent getting back from a little break and continue debugging my speech transformer.
Day 1
Unfortunately my copy of the CommonVoice dataset got deleted, so I spent the day re-downloading and running scripts to setup the dataset again. Luckily everything was scripted, so it didn't take too long!
Day 2
Today was spent mostly debugging why I was getting bad output from my model while training. This was mostly spent debugging the CharacterVocabularly class and its encode/decode functions, to understand how tokenization and decoding was funcitoning and if there was some issue causing these weird output patterns in text as it was passed through the model.
With using_special_chars = True, we get output that looks like this:
Predicted text: ooooooooooooooooooooooooooooooooounknown_charhoooooounknown_charunknown_charhhvvvbsvvvbbboooolllllll...
Actual text: SOShe also fought at the battle of bothwell bridgeunknown_charEOSPADPADPADPADPADPADPADPADPADPADPADPA...
With using_special_chars = False, we get this kind of output:
Predicted text: dddd fffyyfffffdddiooooooffooeeeehhiooooooonnnnniioooooooinnniinnnnniiuueeeeeeexyyyfyjuooeeeeedeuu
Actual text: for example colombia chile argentina and venezuela
Something is happening (or not happening) with the predicted text, so I'll have more sluething to do. Excited to see what I end up learning!
Day 3:
Today was spent writing this long and continuing to debug the model. Something I want to figure out quicker debug feedback loop with starting training, getting output, and stopping the process to free of the GPU memory.
Things for next cycle
I'll be spending the next cycles continuing to train and debug my model. My hope is to get a working demo by the end of the month!
Training
I started training my speech transformer! A cool moment was during some debugging and decoded a tokenized piece of text that I had only seen first as a list of integers first, watching this sentence "emerge" from just numbers.
print("text: ", text)
...
text: tensor([[ 1, 26, 11, 28, 3, 30, 5, 15, 8, 22, 22, 30, 16, 28, 30, 22, 18, 24,
15, 3, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
...
print('string: ', self.cv.decode(text[0].tolist()))
...
string: why bless my soul
I'm dealing with an OutOfMembery error right now, as it seems like there is a bug in my collate_fn() that handles managing frame legnths to 20,000, but they seem to be entering my attention function at a way larger number, causing memory issues (getting attention scores scales quadradically)
audio feature shape: torch.Size([1, 46675, 80])
I'm excited to continue debugging and scale up training until I can get to a full YOLO run, hopefully next cycle!
Day 1
Today I started working on my SpeechTransformerLearner class, which is where training happens (for some reason I feel like calling it learning rather than training even though I know that's the convention).
SpeechTransformerLearner class
The first function I worked on was compute_loss(), which allows us to see whether or not our model is getting any better and predicting words from spectrogram/text pairs used in training/learning.
For speech recogntion, the metric we really care about is Word Rate Error, which is measured by comparing a speech recording and its transcript against what the model predicts the transcript is, only using the same speech recording.
WER is measured by this formula:
# WER = (Substitutions + Deletions + Insertions) / (Total Words in Ground Truth)
And can be calculated by finding the Levenshtein distance between predicted words and the ground truth transcription.
Day 2
Today I worked on more functions for my learner, like:
And a few other helper functions.
I also paired with another Recurser on some virtual machine / devops-y stuff on Heap, which was loads of fun :)
Day 3:
Today I continued working on getting closer to doing my first training run, starting with writing some more code for checkpointing, logging and tracking metrics like grad norm to see if there gradient clipping is necessary, and if so, what value it should be.
I was able to hook my learn() function up to Weights and Biases which was cool to see my training showing up in the dashboard, getting some experience in some MLOps.
Finally I started to get some training off the ground, but encounted some bugs around how my custom batching is working.
I did get to do some fun debugging and fiddled around with decoding some tokenized strings, which was gratifying to see!
This was the first text I got to see come out of decode():
string: dance of fire is a small trilogy
I'm really excited to get this working and scale up testing as much as we can.
Things for next cycle
Next cycle I'm going to continue training, and hopefuly get that working on Ray.
Processing
This was a pretty good cycle with a lot of heads-down work on text and audio preprocessing of the CommonVoice dataset. I also got to pair a bit on some new infrastructure setup on Heap.
Day 1
Today I worked on audio and text dataset pre-processing pipeline for my speech transformer. According to the paper, they used the "Wall Street Journal (WSJ) dataset, training on si284, validating on dev93 and evaluating on eval92 set."
It's not specified in the paper which specific WSJ speech corpus they used, as the Linguistic Data Consotrum offers two: WSJ0 and WSJ1.
Either way, each dataset costs $1,500 and $2,500 respectively for non-members, which is....a bit outside of my budget at the moment :)
So instead, I'm using Mozilla's CommonVoice dataset, which is completely free, open-source, and publicly available speech datasets that is comprised of community-donated speech samples.
I spent a good amount of time exploring the dataset, which you can follow along here:
I also worked on some classes for pre-processing this dataset for training with my speech transformer with a new speech transformer dataset file:
From some of the data analysis, we were able to determine that filtering out speech recordings with sentences > 100 characters would still allow us to use more than 95% of the dataset, which is good for keeping our sequence length tight for efficient training.
self.tsv_items = self.tsv_items[ self.tsv_items['sentence'].str.len() <= self.cfg.max_seq_length ]
I also learned how to use the apply() function in pandas to do efficiently clean up elements in our dataset, like renaming file extensions and cleaning up sentences.
For example, we can write functions like these:
# replace .mp3 with .wav
def replace_mp3_with_wav(path):
return path.replace("mp3", "wav")
# clean sentences
def clean_sentences(s):
return s.split('\t')[0].strip().lower()
And "apply" them like this!:
self.tsv_items['path'] = self.tsv_items['path'].apply(replace_mp3_with_wav)
self.tsv_items['sentence'] = self.tsv_items['sentence'].apply(clean_sentences)
One of the more interesting things I came across while working on this Dataset class was handling normalization. From the paper, they write:
"The input acoustic features were 80-dimensional filterbanks extracted with a hop size of 10ms and a window size of 25ms, extended with temporal first and second order differences and per-speaker mean subtraction and variance normalization."
I was curious to understand more about how this normalization worked and why it was necessary. Asking Claude, I got some answers:
Prompt:
Can you help me with normalization? Still don't provide any code.
Response:
For normalization, we have a few options based on the paper's specification of "per-speaker mean subtraction and variance normalization":
Simple Approach (per utterance):
- Calculate mean across time and frequency for each utterance
- Subtract mean
- Calculate variance
- Normalize by standard deviation
Pros: Simple, no speaker tracking needed
Cons: Not exactly what paper describes
Per-Speaker Approach (matches paper):
- Track speaker IDs from CommonVoice
- Calculate stats across all utterances from same speaker
- Store/cache statistics
- Apply during getitem
Pros: Matches paper exactly
Cons: More complex, needs speaker management
Global Statistics (alternative):
- Calculate stats across entire dataset
- Store in dataset class
- Apply same normalization to all samples
Pros: Simple, consistent
Cons: Loses speaker-specific characteristics
For best results, we should implement the per-speaker approach. This would need:
1. Speaker ID tracking in init
2. Statistics calculation/storage
Lookup during normalization
Would you like me to explain how to implement any of these approaches in detail?
Remember: The paper used per-speaker normalization because different speakers have different acoustic characteristics (pitch, volume, speaking rate, etc.)
I figured out where speaker ID was stored in the dataset (as client_id), but still wanted to understand a bit more about what this normalization would actually accomplish for training purposes. In particular, because of my research on bias in speech recognition systems, I was really curious to know how normalization affected the how the model would handle (or not handle) different acoustic characteristics:
Prompt:
And why do we need to do normalization?
Response:
Normalization is important for several reasons:
- Speaker Variation:
- Different speakers have different voice characteristics
- Some speak louder/softer
- Different pitch ranges
- Different speaking rates
- Different accents/pronunciations
- Model Training Benefits:
- Makes training more stable
- Helps model focus on important features
- Reduces impact of speaker-specific variations
- Makes features more consistent across speakers
- Technical Reasons:
- Brings features to similar scale
- Prevents very large/small values
- Helps with gradient flow
- Makes optimization easier
- Paper's Approach:
- They use per-speaker normalization
- Helps model learn speaker-independent patterns
- Makes model more robust to different speakers
Think of it like this:
- Without normalization: Model has to learn to handle raw differences between speakers
- With normalization: Model can focus on the actual speech patterns rather than speaker-specific characteristics
Would you like me to:
- Show what the features look like before/after normalization?
- Explain different normalization strategies?
- Or continue with implementation?
I ended up going with a more simple approach to normalization, which normalizes on a per-utterance basis.
I'll probably go back and and re-evaluate that approach at a later date to see how it affects model performance. All said though, I was really surprised to learn how normalization works to average out speaker-specific characteristics in order to make training more efficient and effective, which is something that comes up in Mills and Li's research on speech recognition in Vocal Features. Could this be one reason why ASR systems exhibit bias?
Finally, I worked on setting up custom batching with a custom collate function that follows the paper's approach to processing the data for the model:
"In the training stage, the samples were batched together by approximate feature sequence length and each training batch contained 20000-frames features."
More on training next cycle!
Day 2
Today I paired with fellow Recurser on setting up and playing around with Ray, an orchestration infrastructure tool that handles the queuing and running of jobs across GPU machines (among other things). I got to learn a bit more about Kubernetes, SSH tunneling, port forwarding, and got to see a job get initialized on Ray (but didn't run due to some disk space issues on Heap :/ )
In debugging the disk space issue, I learned about ncdu as a prettier way to see and analyze disk space usage.
Day 3:
Today was mostly spent reviewing notes and writing this log.
Things for next cycle
Next cycle I should be training my speech transformer! I'm hoping I can do more stuff with Ray as well (and maybe do my training through its interface?)
Decoding
This cycle I finished up coding the speech transformer from end-to-end :)
The code for the speech transformer looks something like this now:
My encoder looks like this:
class Encoder(nn.Module):
"""Encoder
Input: [batch time_steps freq_bins]
Output: [batch seq_length d_model]
This class processes a batch of spectrograms by:
- Expanding the input tensor by one dimension for channel
- Passing our tensor through a Conv2d block (with ReLU)
- Passing our tensor through another Conv2d block (with ReLU)
- Reshaping out tensor so it has three dimensions instead of four
- Passing through a linear layer so we get an output shape of d_model for the last dimension
- Passing our tensor through a posiitonal encoder
- Passing out query_input through n encoder blocks
- Passing our tensor through a layer norm
- Outputting our encoded output to be used by the decoder (for cross attention)
"""
def __init__(self, cfg: Config):
super().__init__()
self.cfg = cfg
# encoder components
self.repeat = Repeat(self.cfg)
self.conv2d_block_one = Conv2DBlock(self.cfg, self.cfg.n_channels, self.cfg.n_out_channels, self.cfg.conv2d_kernel_size, self.cfg.conv2d_stride, self.cfg.conv2d_padding)
self.conv2d_block_two = Conv2DBlock(self.cfg, self.cfg.n_out_channels, self.cfg.n_out_channels, self.cfg.conv2d_kernel_size, self.cfg.conv2d_stride, self.cfg.conv2d_padding)
self.reshape = Reshape(self.cfg, "b c ts fb -> b ts (c fb)")
self.linear = Linear(self.cfg)
self.positional_encoder = PositionalEncoder(self.cfg)
self.encoder_blocks = nn.Sequential(
*[EncoderBlock() for _ in range(self.cfg.n_encoder_layers)]
)
self.layer_norm = LayerNorm(self.cfg)
# encoder as an nn.Sequential
self.sequential = nn.Sequential(
self.repeat,
self.conv2d_block_one,
self.conv2d_block_two,
self.reshape,
self.linear,
self.positional_encoder,
self.encoder_blocks,
self.layer_norm
)
def forward(self, x: Float[t.Tensor, "batch time_steps freq_bins"]) -> Float[t.Tensor, "batch seq_length d_model"] : # type: ignore
# take in our input spectrograms, encode, and generate encoded outputs to be used by the decoder for cross-attention
assert x.ndim == 3, f"Expected 3 dimensions, got {x.ndim}"
assert x.shape[2] == self.cfg.n_freq_bins
return self.sequential(x)
And my decoder looks like this:
class Decoder(nn.Module):
def __init__(self, cfg):
super().__init__()
self.cfg = cfg
self.character_embedding = CharacterEmbedding(self.cfg)
self.decoder_positional_encoder = PositionalEncoder(self.cfg)
self.decoder_blocks = nn.ModuleList(
[DecoderBlock(self.cfg) for _ in range(self.cfg.n_decoder_layers)]
)
self.layer_norm = LayerNorm(self.cfg)
self.linear = nn.Linear(self.cfg.d_model, self.cfg.vocab_size)
self.soft_max = nn.Softmax(dim=-1) # Apply softmax along the vocabulary dimension
def forward(self, x,
key_input: Optional[Float[t.Tensor, "batch posn d_model"]] = None, # type: ignore
value_input: Optional[Float[t.Tensor, "batch posn d_model"]] = None # type: ignore
):
# take in our input tokens, encode, and generate character embeddings
embeddings = self.character_embedding(x)
encoded_sequence = self.decoder_positional_encoder(embeddings)
assert encoded_sequence.ndim == 3
assert encoded_sequence.shape[1] <= self.cfg.max_seq_length
assert encoded_sequence.shape[2] == self.cfg.d_model
# pass positional encoding into decoder blocks
x = encoded_sequence
for block in self.decoder_blocks:
x = block(x, key_input, value_input)
x = self.layer_norm(x)
x = self.linear(x)
probabilities = self.soft_max(x)
return probabilities
More on the full SpeechTransformer and its classes can be found here:
Day 1
Today I started refactoring the encoder into its own class. Once that was done, I did some refactoring of the decoder as I wrapped up both sides of the speech transformer diagram.
I learned a bit about static type checkers in IDEs.
I developed a deeper understanding of what the signifigance of our sequence dimension, and how this relates to vocab_size and d_model.
In implementing cross-attention in the speech transformer's decoder, we wnat to use the same Attention class to do both self-attention (with just query_input) or cross-attention (with query_input, as well as key_input, and key_input that come from the output in our encoder.
In order to accomplish this, we use a lambda function that lets us pass optional parameters that end up "closing over" and capturing the extra parameters, if used.
If key_input and value_input are empty, we default to useing query_input for calcuating Q, K, and V in our attention function. If we pass in key_input and value_input from our encoder's output, they will be used in their respective functions in the attention function. This way we can support self-attention and cross-attention in the same class/function.
Here's what that looks like in code:
In our decoder:
class DecoderBlock(TransformerBlock):
def __init__(self, cfg):
super().__init__()
self.cfg = cfg
self.layer_norm_one = nn.LayerNorm(self.cfg.d_model)
self.attention_masked = Attention(self.cfg, apply_mask=True)
self.layer_norm_two = nn.LayerNorm(self.cfg.d_model)
self.attention_unmasked = Attention(self.cfg, apply_mask=False)
self.layer_norm_three = nn.LayerNorm(self.cfg.d_model)
self.feed_forward_network = FFN(self.cfg)
def forward(
self,
x: Float[t.Tensor, "batch posn d_model"], # type: ignore
key_input: Optional[Float[t.Tensor, "batch posn d_model"]] = None, # type: ignore
value_input: Optional[Float[t.Tensor, "batch posn d_model"]] = None # type: ignore
) -> Float[t.Tensor, "batch posn d_model"]: # type: ignore
x = self.add_to_residual_stream(x, self.layer_norm_one, self.attention_masked)
x = self.add_to_residual_stream(x, self.layer_norm_two, lambda norm_x: self.attention_unmasked(norm_x, key_input, value_input)) # this layer needs to use encoder outputs as its inputs for keys and values, and use queries from previous sub-block outputs
x = self.add_to_residual_stream(x, self.layer_norm_three, self.feed_forward_network)
return x
And in our Attention class:
def forward(
self,
query_input: Float[t.Tensor, "batch posn d_model"], # type: ignore
key_input: Optional[Float[t.Tensor, "batch posn d_model"]] = None, # type: ignore
value_input: Optional[Float[t.Tensor, "batch posn d_model"]] = None # type: ignore
) -> Float[t.Tensor, "batch posn d_model"]: # type: ignore
# linear map
Q = einops.einsum(query_input,
self.W_Q,
"b s e, n e h -> b s n h") + self.b_Q
K = einops.einsum(query_input if key_input is None else key_input,
self.W_K,
"b s e, n e h -> b s n h") + self.b_K
V = einops.einsum(query_input if value_input is None else value_input,
self.W_V,
"b s e, n e h -> b s n h") + self.b_V
# ...
And as I wrapped up the decoder, I got a better understanding of how our output probabilities ends up as a vocabulary size, predicting what character should come next. This was a bit a-ha moment for me!
Day 2
Today I reactored and tested the full encoder-decoder speech transformer, as well as some of the older tests where I modified the implementation since yesterday.
def test_speech_transformer(model, cfg):
cv = CharacterVocabulary(cfg)
batches = 2
time_steps = 100
freq_bins = model.cfg.n_freq_bins
text_input = "listening is a practice of freedom"
encoded_text_input = cv.encode(text_input)
assert len(encoded_text_input) == model.cfg.max_seq_length
encoded_text_tensor = t.tensor(encoded_text_input, dtype=t.long)
encoded_text_tensor = einops.repeat(encoded_text_tensor, "seq_length -> b seq_length", b=batches).to(cfg.device)
spectrograms = t.randn(batches, time_steps, freq_bins).to(cfg.device)
output = model(spectrograms, encoded_text_tensor)
assert output.shape == (batches, model.cfg.max_seq_length, model.cfg.vocab_size)
Day 3:
Today was mostly spent writing this post and re-factoring some code in my tests, using pytest fixtures.
Things for next cycle
Next cycle will be training, so I'm looking forward to setting up a data processing pipeline and doing my first training run with this model! I also have a few things that are less of a priority, like move some of the asserts in the classes to tests.
Encoding
This was a really productive past few days where I made a lot of progress on this speech transformer.
![]()
A lot of what I'm trying to do is incredibly new for me (building an automated speech recognition system from scratch), and without the benefit of a mentor to help introduce me to a lot of new concepts that I'm not familiar with, I've been relying on using Claude in Cursor to help introduce me to these concepts at a high-level, so I can program it myself. I've explictly asked it to never provide any code, and instead help me build intuition and guide me through implementation through questions and explaination. A sample prompt might look like:
I'm implementing the decoder portion of a Speech Transformer following the paper "Speech-Transformer: A No-Recurrence Sequence-to-Sequence Model for Speech Recognition". I have already implemented: 1. Complete encoder with: - Initial feature extraction (Conv2D layers) - Linear projection and positional encoding - Multi-head attention (with optional masking) - Feed-forward networks - Layer normalization and residual connections Now I need to implement the decoder. According to the paper, each decoder block should have: 1. Masked multi-head self-attention 2. Cross-attention with encoder outputs 3. Position-wise feed-forward networks 4. Layer normalization and residual connections Additionally, the decoder needs: 1. Character embedding layer at the input 2. Final linear + softmax for output probabilities Please help guide me through implementing these components. Don't provide code directly - instead help me build intuition and guide me through the implementation with questions and explanations.
Or I might write a prompt with the image of the model attached and some text from the paper itself:
Hi! Please read the attached prompt and start helping me along. Today I want to finish the implemetation of the decoder. Please don't provide any code, just help me help me build intuition and guide me through implementation through questions and explaination. I've also attached an image of the architecture. Here is the description of the decoder from the paper: "The decoder is shown in the right half of Figure 2. We firstly employ a learned character-level embedding to convert the character sequence to the output encoding of dimension dmodel, which is added with the positional encoding. Then, the sum of them are inputted to a stack of Nd decoder-blocks to obtain the final decoder outputs. Differently from the encoder-block, each decoder-block has three sub-blocks: The first is a masked multi-head attention which has the same queries, keys and values. And the masking is utilized to ensure the predictions for position j can depend only on the known outputs at positions less than j. The second is a multi-head attention whose keys and values come from the encoder outputs and queries come from the previous sub-block outputs. The third is also positionwise feed-forward networks. Like the encoder, layer normalization and residual connection are also performed to each sub-block of the decoder. Finally, the outputs of decoder are transformed to the probabilities of output classes by a linear projection and a subsequent softmax function."
I've found this way of working with LLMs like Claude extremely helpful, and it was something I got introduced to while working through ARENA during my last batch. In one of the notebooks, they encourage us to use LLMs to help understand code or concepts we aren't familiar with or are seeing for the first time, and they explain this distinction between "playing in easy mode" vs "playing in hard mode":
From ARENA, they write:
We'll be discussing more advanced ways to use GPT 3 and 4 as coding partners / research assistants in the coming weeks, but for now we'll look at a simple example: using GPT to understand code. You're recommended to read the recent LessWrong post by Siddharth Hiregowdara in which he explains his process. This works best on GPT-4, but I've found GPT-3.5 works equally well for reasonably straightforward problems (see the section below).
This is where I got introduced to the concept of "playing in easy mode" vs "playing in hard mode":
Is using GPT in this way cheating? It can be, if your first instinct is to jump to GPT rather than trying to understand the code yourself. But it's important here to bring up the distinction of playing in easy mode vs playing in hard mode. There are situations where it's valuable for you to think about a problem for a while before moving forward because that deliberation will directly lead to you becoming a better researcher or engineer (e.g. when you're thinking of a hypothesis for how a circuit works while doing mechanistic interpretability on a transformer, or you're pondering which datastructure best fits your use case while implementing some RL algorithm). But there are also situations (like this one) where you'll get more value from speedrunning towards an understanding of certain code or concepts, and apply your understanding in subsequent exercises. It's important to find a balance!
It's been nice finding that balance by learning something new from Claude, and then trying to implement that concept on my own. Then when something like that comes up again, I'm feeling myself getting better at writing a lot of things myself from scratch that I've never seen before, as my intuition continues to grow and new concepts begin to stick :)
Day 1
Today was mostly spent working on the encoder side of the abode diagram. That meant implementing a lot of classes, and writing tests for them. At the end of the day, our SpeechTransformer class ended up looking like this:
class SpeechTransformer(nn.Module):
"""Speech Transformer model that converts speech spectrograms to text.
The model follows the architecture from "Speech-Transformer: A No-Recurrence
Sequence-to-Sequence Model for Speech Recognition" paper.
Architecture Overview:
1. Two Conv2d layers with stride 2 reduce time and frequency dimensions by 4x
2. Linear projection to d_model dimension
3. Positional encoding
4. Transformer encoder blocks
5. Layer norm
Currently encoder-only!
Input shape: [batch_size, time_steps, freq_bins]
Output shape: [batch_size, reduced_time_steps, d_model]
"""
def __init__(self):
super().__init__()
self.cfg = Config()
# encoder components
self.repeat = Repeat(self.cfg)
self.conv2d_block_one = Conv2DBlock(self.cfg, self.cfg.n_channels, self.cfg.n_out_channels, self.cfg.conv2d_kernel_size, self.cfg.conv2d_stride, self.cfg.conv2d_padding)
self.conv2d_block_two = Conv2DBlock(self.cfg, self.cfg.n_out_channels, self.cfg.n_out_channels, self.cfg.conv2d_kernel_size, self.cfg.conv2d_stride, self.cfg.conv2d_padding)
self.reshape = Reshape(self.cfg, "b c ts fb -> b ts (c fb)")
self.linear = Linear(self.cfg)
self.encoder_positional_encoder = PositionalEncoder(self.cfg)
self.encoder_blocks = nn.Sequential(
*[EncoderBlock() for _ in range(self.cfg.n_encoder_layers)]
)
self.layer_norm = LayerNorm(self.cfg)
# encoder sequential
self.encoder = nn.Sequential(
self.repeat,
self.conv2d_block_one,
self.conv2d_block_two,
self.reshape,
self.linear,
self.encoder_positional_encoder,
self.encoder_blocks,
self.layer_norm
)
# decoder components
self.character_embedding = CharacterEmbedding(self.cfg)
self.decoder_positional_encoder = PositionalEncoder(self.cfg)
PyTorch has this really nice construct called nn.Sequential, which let's you stack a bunch of nn.Modules together, and you can simply call:
def forward(self, x: Float[t.Tensor, "batch time_steps freq_bins"]) -> Float[t.Tensor, "batch reduced_time d_model"]: # type: ignore
return self.encoder(x)
And nn.Sequential will call all of the forward methods for those objects! That way you can pass your input just once into your sequential, and your data will flow through all of those layers, sequentially. :)
Day 2
Today I started working on the decoder side of the model, and got as far as writing the classes for encoding/decoding input text (CharacterVocabulary) and creating our embeddings (CharacterEmbeddings). Here is what those two classes look like.
Day 3:
Today I had to handle some non-RC things.
Things for next cycle
My hope is to finish the decoder side of the speech transformer model, and do some more documentation / reviewing what I've been learning. It's been a lot so far! Hopefully by the end of the next cycle we can start training this speech transformer with open datasets like CommonVoice.
Stagnation
I had a hard time programming this cycle. I think I've been a bit intimated diving back into doing hard, scary things and I've been procrastinating a bit during the day. I've found a lot more success coding at night, but I want to do better at coding during the day / pairing with others.
I did manage to do some exercises in Vim, and write a little more code towards my speech transformer.
Day 1
Day 2
Day 3:
class SpeechTransformer(nn.Module):
def __init__(self):
super().__init__()
self.cfg = Config()
def forward(self, x):
#TODO modify this code to return the right output shape once we determine what that is
# Conv2d + ReLu - initial feature extraction
# Conv2d + ReLu - more feature extraction
# Linear - project to d_model dimension (this is where embedding happens!)
# Reshape
x = einops.reshape(x, "b ts d_model-> b (ts fb) feature_dim", feature_dim=self.cfg.d_model) # b ts fb
# Input Encoding (Positional Encoding) - add positional information to embedded sequence
# Attention Blocks - process the sequence
# Layer Norm
# Multi-Head Attention
# Layer Norm
# MLP
# Layer Norm
return x
def forward(
self,
normalized_resid_pre: Float[Tensor, "batch posn d_model"]
) -> Float[Tensor, "batch posn d_model"]:
# linear map
Q = einops.einsum(normalized_resid_pre,
self.W_Q,
"b s e, n e h -> b s n h") + self.b_Q
K = einops.einsum(normalized_resid_pre,
self.W_K,
"b s e, n e h -> b s n h") + self.b_K
V = einops.einsum(normalized_resid_pre,
self.W_V,
"b s e, n e h -> b s n h") + self.b_V
attn_scores = einops.einsum(Q,
K,
"batch seq_q head_index d_head, batch seq_k head_index d_head -> batch head_index seq_q seq_k"
)
scaled_attn_scores = attn_scores / (self.cfg.d_head ** 0.5)
masked_attn_scores = self.apply_causal_mask(scaled_attn_scores)
A = t.softmax(masked_attn_scores, dim=-1) # attention is all we need!
z = einops.einsum(A, V, "b n sq sk, b sk n h -> b sq n h")
result = einops.einsum(z, self.W_O, "b sq n h, n h e -> b sq e")
return result + self.b_O
def apply_causal_mask(self, attn_scores: Float[Tensor, "batch n_heads query_pos, key_pos"]
) -> Float[Tensor, "batch n_heads query_pos key_pos"]:
return attn_scores.masked_fill_(t.triu(t.ones_like(attn_scores), diagonal = 1) != 0, self.IGNORE)
Things for next cycle
Like last cycle, just continuing my working on implementing the Speech-Transformer paper, and trying to practice learning generously more next cycle.
Extension
I'm back at RC for a six-week half batch, continuing my work on building automatic speech recogniton (ASR) systems from scratch for science and fun :)
During my last 12-week batch, I created Zora, an interpretable machine listening library for voice and speech. I gave a presentation on it during the last week of batch that you can check out here. I demonstrated how you can use this library to build a speech digit recognizer i.e. recognizing someone saying the digits 0-9. My goal for this half batch is to build out a full-spectrum ASR system with my library that should be able to do robust speech-to-text recognition.
Towards those ends I've planning on implementing a transformer-based ASR system based on the Speech-Transformer paper. This cycle was spent mostly getting myself set up, as well as participating in first-week-of-batch activities, meeting all the new Recursers, and catching up with familiar faces.
Day 1
I spent most of my day reading the Speech Transformer paper (a more... :cough:...accessible version of the paper can be found here).
Day 2
I started setting up my environment for development, which meant setting up some scaffolding for testing with pytest. I also learned that conda has this weird way of listing dependencies in your requirements.txt file by appending an @ symbol and a local path to that library, which breaks running pip install -r requirements.txt. The way to get around this was by using pip list --format=freeze to generate requirements in the right format i.e. pip list --format=freeze > requirements.txt
I starting writing code to implement the self-attention mechanism, and afterward I had a nice coffee chat with a Recurser before attending first-week presentations
Day 3:
Today was spent attending the "Building Your Volitional Muscles" workshop. I actually feel really good about what I want to focus on, why I want to focus on it, and what that means for deprioritizing other things that I might be curious about doing but might not be as important to me given all the other things I want to do. I know that my deep passion lies with the triangle of audio/sound/music, software engineering, and ML/deep learning. I ended up organizing everything into these buckets:
ASR
Week 1 - Transformer training
Week 2 - Finetuning
Week 3 - Mechanistic Interpretability
Week 4 - Metrics and Evals
Week 5 - Data upload / model weights
Week 6 - Present!
Stretch goals:
Filling gaps in Software Engineering knowledge
Picking up one of these books and doing something with them (either playing on Heap and/or developing some MLOps skills):
I rounded out the day with a meeting for the Heap Computer Club, which went really well. We made a very short presentation about the cluster, how to use it, and how to get more involved, which can be found here.
Things for next cycle
Along with just continuing my working on implementing the Speech-Transformer paper, I want to see if I can slide in some of my other side quests here and there.
I also want to get better at vim, so I'm going to try to watch one video from Primagen's Vim As Your Editor series a da.
Conclusion
This is the last cycle for my current batch at Recurse! Even though I'm technically extending my batch by six weeks, I feel the significance of this 12-week batch ending.
Day 1
Today I worked on my presentation on Zora! As part of that, I ended up generating a lot of cool gifs like the one below:

Day 2
Today I presented on Zora, my interpretable machine listening library for voice and speech.
Here is a link to my presentation: Zora: An Interpretable Machine Listening Library for Voice and Speech
Day 3:
Last day of batch! I basically just worked on this log post, along with spending time with my fellow RCers before we all go off on our post-batch journeies ;_;
Things for next cycle
That's it for now. Looking forward to my six week batch extension :)
Conversation
This cycle was mostly occupied with an all-day AI Safety Workshop that I atteneded at RC.
Day 1
I attened an AI Safety Workshop at Recurse Center.
This one slide really stuck with me

Day 2
I did some non-RC things on this day.
Day 3:
I worked on my Zora presentation, for next Thursday (last cycle of this batch)
Things for next cycle
Next cycle is my last one for my second batch! ;_;
Dimension
This cycle was mainly working on Zora, finishing up some data pre-processing on Heap (as well as fixing some Ansible code!).
Day 1
I worked on a bug in the Ansible code that manages the Heap cluster, debugging a nested for loop that can be improved with some proper data structures.
I finished CommonVoice data preprocessing. The directory of wav files, produced from the mp3 files, totals 390GB :) Compare that to the zipped version of the download, which was only 84GB.
(base) jo@broome:~$ du -sh /data/jo/commonvoice/*
84G /data/jo/commonvoice/commonvoice.tar.gz
483G /data/jo/commonvoice/cv-corpus-19.0-2024-09-13
(base) jo@broome:~$ du -sh /data/jo/commonvoice/cv-corpus-19.0-2024-09-13/en/*
79M /data/jo/commonvoice/cv-corpus-19.0-2024-09-13/en/clip_durations.tsv
92G /data/jo/commonvoice/cv-corpus-19.0-2024-09-13/en/clips
390G /data/jo/commonvoice/cv-corpus-19.0-2024-09-13/en/clips_wav
4.7M /data/jo/commonvoice/cv-corpus-19.0-2024-09-13/en/dev.tsv
92M /data/jo/commonvoice/cv-corpus-19.0-2024-09-13/en/invalidated.tsv
104M /data/jo/commonvoice/cv-corpus-19.0-2024-09-13/en/other.tsv
1.3M /data/jo/commonvoice/cv-corpus-19.0-2024-09-13/en/reported.tsv
4.7M /data/jo/commonvoice/cv-corpus-19.0-2024-09-13/en/test.tsv
352M /data/jo/commonvoice/cv-corpus-19.0-2024-09-13/en/train.tsv
456K /data/jo/commonvoice/cv-corpus-19.0-2024-09-13/en/unvalidated_sentences.tsv
223M /data/jo/commonvoice/cv-corpus-19.0-2024-09-13/en/validated_sentences.tsv
555M /data/jo/commonvoice/cv-corpus-19.0-2024-09-13/en/validated.tsv
Day 2
I started porting training code to Zora library.
Day 3:
Today was more porting of training code.
Things for next cycle
I'm going to start working on my presentation for Zora, continue working on the library, maintaining Heap, and finding time for some other fun programming :)
Extension
Most of this cycle was spent with family, so I leaned into that more than anything else. I made a bit more progress on working with the Common Voice dataset (more below). More importantly, I think I decided I want to extend my batch at RC for six weeks! I'm going to check in with the RC faculty next cycle and see if that would be possible.
Day 1
I did a silly thing and screwed up my data preprocessing for the Common Voice dataset. The dataset comes as mp3s, so I tried to convert them to wavs with a new sampling rate of 16000. Unfortunately the code I wrote ended up stretching the audio out, so not only did it completely balloon the wav version of the dataset to about 2 terabytes (yikes), it also made all of the audio unusable. So, I rewrote the code, and I'm now reprocessing all of the files again. Lessons learned!
Day 2
Today was mostly spend re-processing the Common Voice data set.
Day 3:
I'm still continuing to re-process the dataset, which is just about halfway done.
It's also December 1st, which means Advent of Code is starting. I've never done it before so I dedided to try it out. My main intentions are for me to practice Python and have a little fun doing this while hopefully stretching myself a bit as a programmer through the process.
Things for next cycle
For the next few cycles that wrap up my current 12 week batch, I want to:
Transportation
This cycle I flew back home to Florida to be with my family for the holidays, so I've been spending most of my time with them. I did manage to get a few things done however, which is exciting.
Day 1
Today was mostly spent working on getting set up to download the Common Voice dataset and preparing myself to work with it. Some code around downloading, extracting, and converting the mp3 files to wav files can be found in this notebook.
Day 2
I worked more on Zora and created some fun classes and functionality, including a listener class that has two main functions, listen and interpret.
import numpy as np
import torch as t
class Listener:
def __init__(self, model_architecture, model_weights, interpreter):
self.model_architecture = model_architecture
self.model_weights = model_weights
self.interpreter = interpreter
def load(self):
# get our device
device = t.device("cuda" if t.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# load the model
self.model_architecture.load_state_dict(t.load(self.model_weights, map_location=device))
# load the interpreter
self.interpreter.load(self.model_architecture)
def listen(self, spec):
# Pass spec into model
outputs = self.model_architecture(spec)
prediction = str(outputs.argmax().item())
print("Model prediction:", prediction)
def interpret(self, spec):
self.interpreter.interpret(spec)
Day 3:
Today I started working on downloading the Common Voice dataset for my transformer-based ASR model. It's going to take.... a couple of days to convert the 2459129 mp3 clips into wav files, so we are now sitting back and waiting for that to happen.
Things for next cycle
A little bit of the same for next cycle: working on Zora, working on ARENA and helping out with Heap.
Gestation
This cycle was a lot of work related to starting my library called Zora. It's an interpretable machine listening library focused on voice and speech. You can learn more about Zora, my values and intentions around the library, and ways to contribute here!
Day 1
Today was focused mostly on non-RC related activities
Day 2
Today I worked on Zora and made some nice progress. I also started on an implementation of a transformer-basesd ASR system based on the Speech-Transformer paper.
Day 3:
Today I tested some new set up on the Heap cluster. Some other Recursers set up a new 10TB HD that can be accessed from other machines, which is a huge boon for the cluster at large.
Afterward I had a nice pairing session with another Recurser around my library. I was prompted to explain how convolutions work and what were seeing in some of this feature visualization work I'm doing. It was really nice trying to explain these concepts out loud, and I arrived at some language around convolutional layers generating a "low resolution, but highly information dense" representation of an input as it passes through the network.
Here are some first attempts at visualizing the activations in this CNN trained on speech digit information (this is for the number 6):

They also were excited by how the library makes possible specific, low-latency, and local-first machine listening, which was always a desire! Not having to be connected to the internet could make the library appealing in settings where one doesn't have reliable access to the internet.
Finally we chatted about how interpretability functionality allows the user of the library to get more direct interpretation of what is going on in the model, especially around more "non-visual" data like sound, verses having to just guess based on what you hear (which could be more unreliable).
Things for next cycle
For next cycle, it will be much more of the same: working on this library, working on ARENA and helping out with Heap.
Continuation
I'm back from my retreat in Puerto Rico, and started to get back into Recurse activities at the end of this cycle.
Day 1
JT retreat
Day 2
JT retreat
Day 3:
Today I worked on ARENA, Heap, and wrote my first Python library with a fellow Recurser.
Things for next cycle
For next cycle I'll be focusing back on my ASR library, getting back into ARENA, and doing work on Heap.
Vacation!
I'm at a retreat for my fellowshp in Puerto Rico! My favorite conversation with a co-fellow was about the future of space engineering.
Day 1
Today I read the Speech-Transformer paper and started a repo for Zora.
Day 2
Today I panted my studio.
Day 3:
Today I checked in about installing a new harddrive on Heap.
Things for next cycle
I'm going to start working on my ASR library Zora next cycle.
Reflection
This was another contemplative, introspective cycle. I think I needed a little distance from ARENA and some time to work leisurely on Audrey, while thinking towards my larger goals for my time at RC, with half of batch to go.
I decided to work on a library called Zora, which will be an automatic speech recognition (ASR) library and platform focused on interpretability, openness, and personalization.
I also had some time to think about my relationship to RC's self directives. In short, I've been feeling the tension between working at the edge of your abilities and building your volitional muscles. I think that sometimes at certain moments, or over long, sustained periods of time, working at the edge of your abilities may not be the thing you necessary want to do, in service of staying at that edge. It often may no longer be grounded in curiosity nor joy. I think I've been motivated mostly through curiosity, but at times not felt joy as much as I would like, especially when working on really hard things. I'm working on re-finding that balance between the two... I think spending some time this cycle on reminding myself of the why is helping re-energize and re-motivate me in the what* that I'm doing.
Day 1
Day 2
Day 3:
Things for next cycle
I'm going to spend some time working while preparing for my upcoming Just Tech retreat to Puerto Rico!
Direction
This cycle was a little direction-less. I'm feeling the slog of ARENA kick in, and I'm trying to think about what I want to do next for my Audrey project / ASR self-study. A bit of a light cycle on work, so not too many updates.
Day 1
I worked on Heap with some Recursers and was able to improve the system with respect to updating ssh keys for users.
Day 2
Today I chipped away more on mechanistic interpretability, with respect to identifying different kind of induction heads and circuits.
Day 3:
Not much was done on this day.
Things for next cycle
For the most part, I just want to continue on with ARENA, ASR self study, and Heap. Also, we'll be welcoming in a new batch!
Transition



This cycle was travel-impacted, as I went to Indiana University to give an artist talk and take part in a roundtable discussion with artists and scholars in support of Blurring the Lines: Art at the Intersection of Human and Artificial Creativity, a group exibition I'm showing work in at IU's Grunwald Gallery.
It was a great experience and I'm really glad I went. Therefore, not much RC work was attended to this cycle. I'm am happy for some of the mental space it did give me, and I'm feeling even more inspired and motivated to continue the work I'm doing :)
Day 1
On Induction Heads
I spent most of the morning learning about Induction Heads and Circuits from these two resources:
Day 2
Today was a travel day for me to Bloomington, Indiana.
Day 3:
I gave a talk and joined a roundtable for the exhibition, and just got home not too long ago.
Things for next cycle
I'll be continuing on with ARENA, and I have some ideas around building an audio ML library, with Audrey being one of the examples :)
Interpretation
This cycle was spent starting mechanistic interpretability, training my automatic speech digit recognizer based on Audrey, and contemplating how to best work on and maintain the Heap machines.
Day 1
On Mechanistic Interpretability
I worked on using TransformerLens to look inside of a pretrained GPT-2 model and begin the practice of mechanistic interpretability!
Day 2
Today I worked a bit more on mechanistic interpretability, but quickly realised that there was a lot more required reading I needed to do in order to get through the next section, so I instead decided to procrastinate reaeding at RC to work on Audrey a bit more. I'm delighted to say I got it training and working! It doesn't generalize well to my voice, so I'm going to go back and make a dataset derived just from my voice, so that my trained model works uniquely for me. I'm realizing that it might be very easy to imagine a world where everyone just has their own personal weights for models, and you could just pipe that into the model, given its archiecture, and have it would exceptionally well for you. I'm going to explore this idea more during the rest of my batch...
Day 3:
Today I took some time to reflect and sift through the large amount of Neel Nanda content out there. As I'm working through this material on mechanistic interpretability and reverse-engineering transformers, I'm trying to organize a sequence of things to read in order to keep up.
These two feel like the first places to start / read:
These are some videos that I think would be next in line to watch:
A Walkthrough of A Mathematical Framework for Transformer Circuits video
A Mathematical Framework for Transformer Circuits paper
A Walkthrough of In-Context Learning and Induction Heads video
In-context Learning and Induction Heads paper
And then these are more around context and open questions in the field - more optional but really help to set the stage and articulate the stakes of working on this problem:
Things for next cycle
For the reset of Chapter 1 in ARENA, we get to choose what to do next, given a set of exercises. I'm interested in superposiiton, so I'm excited to check out resources like this one on Toy Models of Superposition.
I also want to go back and think about transformers a bit more deeply.
I had a really great conversation with two Recursers about audio classification, neural network architectures, and other things. As I'm finishing up this first pass on a simple ASR system, we were thinking about interesting challenges we could work on. One could be solving audido CAPTCHA challenges. As someone who has been on the internet for a very long time, I couldn't believe I had never encountered the audio version of CAPTCHAs before!
I'm wondering if it might be a fun challenge to build a Reinforcement Learning (RL) project that learns to solve these audio CAPTCHA challenges....something to think about for the second half of my batch when we get to RL with ARENA.
Some thing I want to do for Audrey include:
Along with using my own voice, I'd like to spend some time looking at this Audio MNIST dataset.
I'm also thinking about the architecture I should choose in building my transformer-based ASR system. It seems like the Conformer is what I'm looking for. Some resources include:
There are other, non-CNN architechtures as well:
Transformation
![]()
This cycle was a lot of pairing on transformers. For example we implemented a Transformer Block like the one diagramed above.
Day 1
I was offline doing non-RC things :)
Day 2
Building and Training Transformers
I paired today on building an implementation of GPT-2 from scratch!
Stanford CS25: V2 I Introduction to Transformers w/ Andrej Karpathy
Day 3:
Following up from yesterday, I did more pairing on transformers, this time learning different methods for sampling from a pretrained GPT-2.
How to generate text: using different decoding methods for language generation with Transformers
I also worked more on Audrey! I'm hoping to present something around Week 7.
Data Augmentation Techniques for Audio Data in Python
Things for next cycle
I want to focus on ARENA, Audrey, and helping support Heap!
Automatic Speech Recognition with Transformer
Things to research
Optimization, Propagation, Variation, Generation, Discrimination
Day 1
I'm still super happy about what I learned about CNNs and ResNets last week!
Here's another short explainer on how ResNets work.
I finished the optimization section in ARENA and started moving into backpropogation.
I learned a lot of new things, including:
On Optimization
I also spent a bit more time workin on Heap, and realize that I need to learn more about Ansible and how it works in order to be better and making improvements/updates to Heap in the future.
On Backpropagation
After finishing the backpropagation section in ARENA, I started pairing with a fellow Recurser on generating a synthetic speech dataset that contains speakers saying the numbers 0-9, as a way to start building a simple audio speech classifier from scratch.
Some resources:
Day 2
On VAEs and GANs
Today we started learning to build and train Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs)
I started learning about building and training GANs today, and will have to finish that up on the first day of my next cycle.
Day 3:
Things for next cycle
I have a small bit of work on GANs to finish at the top of the week, which I'm looking forward to getting past, because...
Next we we will learn to build Transformers and start getting into mechanistic interpretability! I've been preloading my brain with a lot of resources on the topic, linked below. Really looking forward to getting my mind blown next week :)
On AI Safety
On Mechanistic Interpretability
Normalization
This cycle was mostly spent with ARENA and NNFS. I've been spending a lot of time thinking about what to do post-ARENA, which lead me to think a lot about why I'm even doing ARENA in the first place. I dug around a lot more into AI safety, and I think I'm motivated by interpretability and observability of models. I'm interested how some of this work will translate to voice based models and agents, as that really feels like an under-explored area that I would have a lot of fun figuring out with opportunities to make novel contributions.
Day 1
I built an implementation of ResNet34 from scratch, and it was super exciting to have it all come together.

I also just had tons of fun debugging the network, seeing how many parameters it contained, and delightfully moving through the code in order to get it to work correctly. I found a lot of joy in that kind of low-level ML engineering, and could see myself having lots of fun doing that kind of work professionally.
Here is what my ResNet looked like with some layers missing

I had a really subtle bug where I was returning a list to my BlockGroup class that didn't match the size of other params that I was zipping up in order to determine the number of layers in my BlockGroup.

After a bit of debugging I realized that my in_featers_per_group was missing two entries. It turns out that I was returning just the first two elements of the list by saying self.out features per group[:1], but I just wanted to get a list without the last element, in which case I meant to write [:-1] instead of [:1]. So subtle yet so crucial!

I made the fix and got the right size so that my zip function would create four BlockGroup objects instead of just two.

And here's what it looked like once I properly got those layers networked together.

After finishing this, I started to realize that I now have enough skills to start building my own speech classifier, and that would be a really fun and exciting thing to work on as we finish up all of these pre-requisite, foundational excercises for AREA.
Day 2
Today I started working on the Optimizers chapter in AREA, and also started watching videos related to AI safety, just to get a better sense of the field.
I also made some much-needed improvements to Macaw, including adding paper authors to the show description.
Day 3:
Today I worked more on Optimizers and paired with a Recurser on Ansible setup on Heap :)
Things for next cycle
Convolution
Another cycle that was motly focused on ARENA plus working through the Neural Networks from Scratch book.
Day 1
Today was Impossible Day at RC, so I started by finishing Chapter 5 in NNFS and then worked through translating this tutorial on building an ASR system with a Transformer model from Keras to PyTorch. I got it mostly done, but wasn't able to get it running on Heap due to some issues with Heap's Python environment. Something to work through on another day :)
A fellow Recurser also presented on FFTs and showed off their guitar tuner written in C!
Day 2
Today was the start of working on Convolutional Neural Networks
And then I wrapped up finishing Chapter 6 in NNFS
Day 3:
This morning a fellow Recurser introduced me to Piper, a text-to-speech program that can run on a Raspberry Pi. Something to look into and play with!
In our ARENA check-in call, we talked about the following projects:
Today I continued working on CNNs and encounted the followint topics:
Things for next cycle
Transposition
This cycle was consumed by ARENA, plus work from the Neural Networks from Scratch book/videos. I did a lot of work with tensors, einops, linear algebra, and manipulating matrices. I'm still trying to build up an intuitive feeling for thinking and programming in this way, so I'm taking every mistep as a sign that I'm really working at the edge of my abilities - whenever I have to learn something new, I take it as evidence of that fact. And I learned a lot of new things.
Day 1
Today I started the exercises for ray tracing
I was also able to pair with another Recurse and get onto the GPU machines on Heap :)
Day 2
I worked through Neural Networks from Scratch (NNFS) Chapters 1 and 2
I also learned more about PyTorch for manipulating tensors, matricies, vectors, arrays...
vs.
Day 3:
Today I finished the ray tracing exercises, with some help from an AI assistant (I use Claude Sonnet 3.5). The exercises actually recommended we do that, and it was nice to work with something (I almost wrote someone) that I can share ideas and approaches with, confirm my intuition, and help lead me to the right implementation. This was super helpful, because these last exercises were pretty chanllenging for me. We dealt with 2D rays and seeing if they interset with triangles. All of this was meant to help build up to a function that rendered a mesh of Pikachu.

Some more PyTorch functions that I came across:
I also came up against broadcasting, which I need to spend more time internalizing.
Lastly I finished NNFS Ch 3
Things for next cycle
Submersion
This cycle was a bit intense, and I feel less like I'm immersing myself in ML/AI studies and instead I'm fully submerging myself into it, like diving into a deep, wide ocean with no intention of swimming back up to the surface. A lot happened this cycle, but strangely I don't have too much to write about it for the time being. I spent the first two days of this cycle moving through online videos on linear algebra, and all of my notes are in my notebook for now. Which meant I did very little coding. But on the last day of this cycle, I did get around to some coding, through the lens of learning about einops. More details below...
Day 1
I watched 3Brown1Blue's Essence of Linear Algebra videos and took copious notes.

Day 2
At the Audio HangShared my Speech Emotion Recognition notebook in the Audio Hang group, and got into a conversation about audio signal feature extraction and clustering, especially around mel-frequency cepstral coefficients. We also talked a lot concatenative synthesis and granular synthesis, and another Recurse showed off one that they built from scratch in Rust and JS :)
Later on in the day I finished all of the Essense of Linear Algebra videos :) As I get deeper into Linear Algebra, I'd love to check out this book: Linear Algebra Done Right.
Day 3:
For the AI ML Paper Cuts study group, we read the now-classic Attention is All You Need which popularized both self-attention mechanisms and transformer models. I watched a couple of videos to help complement the paper, including Illustrated Guide to Transformers Neural Network: A step by step explanation and Attention Is All You Need over by Yannic Kilcher.A lot of it was over my head, but I was happy to expose myself to it this early, and at the very least I could follow and understand the implications of the paper. I'll be excited to revisit this paper once I have a firmer understadning of the fundamentals that lead up to it. In particular, there was some discussion on understanding some of the transformer's sublayers a bit more in depth.
It was mentioned in the call to check out 3Blue1Brown's videos on Neural Networks to get some basics on neural networks in an intuitive, visual way. This annotated version of the Transformer paper also seems like a great resource, especially for its visualizations of positional encodings.
Next week we are scheduled to read Learning Transferable Visual Models From Natural Language Supervision, which introduces Contrastive Language-Image Pre-training. I'm super interested in learning about this idea because it lead to Contrastive Language-Audio Pre-training, which makes possible text-to-audio systems introduced in the analogous paper CLAP: Learning Audio Concepts From Natural Language Supervision. So while I have a lot of things going on already, it would be nice to try to keep up with that paper because of its implications to other areas that I'm currently interested in with respect to audio machine learning.
In the afternoon I worked through an ARENA pre-requisite on einops, a Python library for tensor manipulaton that prioritizes readability and explicitness. It is based on Einstein notation I worked through the einops basics and started to develop an intuitive feel for how the library works, compared to NumPy or PyTorch. This intro video to einops was also very helpful for getting a fuller sense of its usefulness. Some other resources I came across include this article on einops in 30 seconds (早い!), this Reddit post on how to read and understand einops expressions, and two resources sharing a similar, catchy title: Einsum is All you Need - Einstein Summation in Deep Learning and Einsum Is All You Need: NumPy, PyTorch and TensorFlow.
As a way to encapsulate all of the ML/AI self-study I'll be doing (and have been doing), I created a monorepo to contain all of the topics that I'll be learning as a one-stop-shop for all things related to ML/AI.
Things for next cycle
Attenuation
Day 1
As a way to get back into Data Strctures and Algorithms (DS+A) studying, I hopped into the #daily-leetcode channel and saw that there is a bot that posts a new problem a day, one from Leetcode explictly, and one from Grind75 / technicalinterviewhandbook.org. So I thought I'd start with that to slowly get my feet (fingers?) back into the water...
I'm going to be publishing my DS+A study notes on this blog, as a single post for each category / topic. So you might see some posts called "Array" or "String" or "Matrices" that I plan on updating as I continue on with my studying, with code and key insights from some of the coding problems I do.
I had a nice chat with a fellow Recurser who shared that I might consider looking into seq2seq learning models in order to do some interesting voice synthesis, as it can learn a distribution of voices and re-generate voices from that distribution. Something to look into...
Finally I made some progress on my Speech Emotion Recogntion notebook that I hope to use for an upcoming class I'm proposing at ITP. More on that soon...
Day 2
I also got pulled into an AI/ML study group that is working through the ARENA material. I'm excited to work with these folks, and get my self-study going towards my ASR project.
For next cycle, I'll be working through:
Finally at the end of the day I worked a bit more on a personal project that I hope I can share more about soon ... ~~~~
Day 3:
I worked from home on Day 3 of my cycle, and reviewed some materials around ARENA, did a leetcode problem on matrices, and updated my personal website and this blog.
That's all for this cycle check-in!
Matrices
class Solution(object):
def setZeroes(self, matrix):
"""
:type matrix: List[List[int]]
:rtype: None Do not return anything, modify matrix in-place instead.
"""
list_of_zeros = []
width = len(matrix)
height = len(matrix[0])
# find the 0s in the matrix
for x in range(0, width):
for y in range(0, height):
if matrix[x][y] == 0:
# what should we do when we find a 0?
# naive approach, store loc in a list, and then once we've scanned the matrix, go back and set the rows/cols for that location to 0
list_of_zeros.append([x, y])
for loc_of_zero in list_of_zeros:
def set_row_col_zero(loc):
x = loc[0]
y = loc[1]
# set row to zero
for r in range(0, width):
matrix[r][y] = 0
# set col to zero
for c in range(0, height):
matrix[x][c] = 0
set_row_col_zero(loc_of_zero)
Stacks
class MyQueue(object):
def __init__(self):
self.stack_1 = []
self.stack_2 = []
def push(self, x):
"""
:type x: int
:rtype: None
"""
self.stack_1.append(x)
def pop(self):
"""
:rtype: int
"""
while self.stack_1:
self.stack_2.append(self.stack_1.pop())
popped_value = self.stack_2.pop()
while self.stack_2:
self.stack_1.append(self.stack_2.pop())
return popped_value
def peek(self):
"""
:rtype: int
"""
return self.stack_1[0]
def empty(self):
"""
:rtype: bool
"""
return len(self.stack_1) == 0
Arrays
class Solution(object):
def twoSum(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: List[int]
"""
complement_index = {}
for i, n in enumerate(nums):
print(i, n)
complement = target - n
print(complement)
complement_index[complement] = i
for i, n in enumerate(nums):
if n in complement_index and i != complement_index[n]:
print(n)
return [i, complement_index[n]]
Strings
class Solution(object):
def longestPalindrome(self, s):
"""
:type s: str
:rtype: int
"""
pairs = set()
counter = 0
for c in s:
if c not in pairs:
pairs.add(c)
elif c in pairs:
pairs.remove(c)
counter += 2
if pairs:
counter += 1
# a string that can't be a palindrome will just return 0
return counter
Reunion
I'm back at Recurse Center :)
My first day at Recurse Center is caught in the middle of my cycle format, so this is a bit of a shorter first post.
So, to start, to those just arriving, here's a little about me and what I'm planning on doing at Recurse this time around (cross-posted in the Zulip #welcome channel)
--
Hi everyone! My name is Johann :) This is my SECOND batch at RC and I am beyond thrilled to be returning this fall/winter :)
I'm an artist, engineer, and educator based in NYC (so I'll be coming to the Hub most of the time). I'm focused on topics like machine listening, computational audio, and programmatic sound. I like to use technology for creative and artistic means, which sometimes looks like: making musical instruments like the Harvester, building environmental sound classifiers like Whisp, and writing software to generate multi-channel sound installations from large speech datasets. A bit more about me and my last batch was written about on RC's blog.
Right now I’m currently halfway through a two-year fellowship at the Social Science Research Council, called Just Tech.
During my time as a fellow I’ve been researching the origins of bias in automatic speech recognition (ASR) systems used widely in voice interface technology. In the pursuit to dive deep and push myself as a programmer, I wanted to return to RC and do another batch in order to dedicated time and space to learn how this technology works, through building an open-source ASR system from the ground up. Returning to RC for a batch feels like the perfect place to dedicate myself to the work of programming this system, alongside a community of talented and curious programmers with whom I can be in supportive community with.
My goals for this next batch include developing an open-source automatic speech recognition system, trained with public datasets on RC’s GPU cluster Heap. In the process of self-teaching, I plan on putting together a self-study guide on building these types of systems. I’d also be doing associated research on the history of speech technologies to help contextualize the technology I’m building.
Alongside these goals, I will be preparing for the job market post-fellowship, and will be spending time preparing to move into an AI/ML engineering career path. This will involve studying for technical interviews and learning fundamental concepts needed to pursue a career in this field.
I've been pretty active on Zulip in the past, so I plan on documenting this work regularly on Zulip and my blog (you are here!).
Really excited to meet all of you next week!!! Never graduate (I certainly didn't hah)
--
My to-do for my follow cycles:
Daily Ambition:
- 2 hours: DS+A
- 4 hours: ASR Deep work
- 2 hours: Self-Study Guide
Tasks:
- Get set up on Heap, RC's GPU cluster
- Download some datasets
- Put together a plan for DS&A study, ASR buildout, Self-Study Guide, and ML/AI professional development
Some things that I feel like will guide my self-study this fall / winter:
- https://medium.com/bitgrit-data-science-publication/a-roadmap-to-learn-ai-in-2024-cc30c6aa6e16
- https://github.com/iconix/openai/blob/master/syllabus.md
- Ilya’s list
- https://huyenchip.com/ml-interviews-book/
Intro
It’s rare to be able to choose how you show up in the world. We are born into a world already made up with systems, norms, and conventions that prescribe how we must move through the world, organize our time, our bodies, and ourselves. So many of these systems go unnoticed, taken for granted, and, even if ever made aware, unchallenged as we try to simply navigate the world in ways that benefit us. Don’t stir the pot too much, one might think. And so we go on living our lives without possibly considering what alternative ways of living are available to us - ways that might be more conducive and more agreeable to us, more harmonious, more beneficial, more fruitful, happier, more productive. A way of living that allows us to feel more satisfied, reach our goals and potential, and live our truest, happiest days.
Through my own hard work, I’ve been gifted the opportunity to explore a new way of living in the world. This framework has two parts: One might be thought of vertically, in which I organize my day (and life more generally) into three main activities: study, make, and play. The other part is an reorganization of containers of conventional linear time, in which I’ve gotten rid of the concept of the “week”, and instead organize recurring chunks of days into four-day cycles, with three working days followed by a rest day. I’ve been running this program since January 1st, 2024, and I’ve already seen so many positive outcomes, along with the rub that comes from moving at your own rhythm against the dominant system of the world. In the next two paragraphs, I’ll explain a bit about these two parts, and then afterwards I’ll reflect a bit on this transition, how it has impacted by life thus far, and other musing on what it means to design a life setup that is more conducive to a desired way of moving through the world.
Study, Make, Play
The idea of Study, Make, Play is indebted to and borrowed from the writings of Annika Hansteen-Izora, who introduced me to their idea of “Dream, Learn, Create”. As I interpret Hansteen-Izora’s formulation, a fulfilling, creative life is made from first imagination, then studying the thing that you imagine and how to realize it, and then the act of creation. I love this formulation, but the ordering is different for me. Instead, I like to think of my creative process as beginning in study - learning about things and thinking about what could become possible (very similar to imagining and dreaming I guess, but firmly rooted in study first). Then I like to make. Make, make, make. I’ve written about making before, but essentially the idea is to just make as much as possible, to see as many variations on idea as you can, to get rid of bad ideas as quickly as you can so your good ideas can arrive, and to think through what your making by making and by examining things outside of your head and in reality. By that I mean, don’t be critical of ideas before you explore them and try them out in the real world. Making something, holding it in your hand, examining it as something that exists materially (however you want to interpret that) will give you deeper insights into what your doing that trying to examine ideas in the abstract. Finally, there is the act of play. After making, play with what you make. Bring it into the world, and experience how it resonates with yourself and others. This is where the fun and joy of creating lies. And this is where I see my work showing up in the world more and more. The acts of studying and making resulting in objects and experiences of play. The end result for me, whether it is performance or productions or sculptures or instruments or installations, is eventually something that is an creative expression from those proceeding activities.
This for me is the creative process that I subscribe to: study, make play. And I try to do each one of these things each and every work day, when I’m not resting. I dedicate one two-hour block of time for each day, so I can go deep and be undistracted. I also leave another two-hour block of time in my day to joy work, which can be anything I want, which might end up being more studying, making, and playing. This framework is how I organize my creative life, and how I intent for it to show up in a single day. But what about a series of days? How do I organize multiple days in order to sustain this practice and remain consistent? Let me introduce the idea of the cycle.
The Cycle
These days, when someone asks me what’s new, I tell them, “Well, I have something kind of unusual to share, so bare with me…..I’ve abolished weeks from my like.” It’s a strange sentence to say out loud, and I usually have to repeat it a few times because, understandably, its not a series of words many people hear, and the idea itself is not something that I’ve even come across myself. But the idea is simple enough to explain.
Essentially, I don’t organize my life and its temporality around weeks anymore. The concept of weekdays and weekends no longer apply to me. Even that alone is a curious frame to think about. I don’t have a five day “work week” anymore. I also don’t have weekends anymore. So how am I setting myself up now? I’ve organized my time into a cycle that contains three work days and one rest day. So now, I dedicate three days to work, which contains the morning dedicated to physical and mental health (fitness, nutrition, meditation, journaling, checking in on community/socializing), and then the rest of the day is dedicated to Study Make Play (SMP), finishing with a dedicated block of time for joy work. My rest day is an active rest day, where I intentionally sleep in, run my normal morning routine sans fitness, and engage in nourishing activities that bring joy, rest, relaxation. They should be reaffirming and offer a moment to reset. Activities include things like writing (like I’m doing right now, on my rest day), studying and practicing hobbies (Japanese, bass guitar), buying groceries and meal prep, and other low impact activities. The idea is not to work, and allow my brain to re-find equilibrium after bring stretched for three days. It also offers me a day to not produce, and instead to simply think, synthesize, and process all of the things I’ve done three days prior, and start to slowly anticipate and get excited for the three days ahead.
There are some observations to make about this system. One is that, technically speaking, I now work on average six work days a “week”. Depending on when/how you count, sometimes I work five days a week. But in general, I technically work more than I did before on the conventional five-weekday/two-weekend week system. In that sense I’m marginally more productive. And yet, I don’t feel any more burned out or overworked than I used to. In fact, I feel way more aligned and “in a flow” than I used to. I think this is due to the more frequent and consistent rest day. Instead of working five days in a row, and getting to the weekend with two days to do anything else but work, I would find myself exhausted and almost unable to do anything other than cram the weekend with all the things I couldn’t get to during the week, and/or just spend the weekend holed up at home, resting and lying in wait for the work week to resume. There is something about the more frequent rest days that break up the three days that feels to make the work less taxing on the mind and body. And I think knowing that a rest day is coming every three days makes the wait and anticipation that much easier to deal with, as opposed to a five day marathon of days that start to blur together. It’s a lot easier for me now to sit and focus on work for these concentrated three-day periods, and then be able to unapologetically let go for a day to properly rest and reset for the next set of work days.
Conclusion
As I’ve only been committed to this creative lifestyle and workflow for just about a month, I’m still learning its pros and cons, opportunities and challenges.
There are some possibly obvious challenges to this. One of which is that, 99% of people and systems in the world don’t operate in this way, and so there is sometimes friction with others when trying to align my system with theirs. Things like going out or staying up late with others can be a negotiation because my last work day of a cycle might not align with someone’s “weekend”. Having to explain to friends that I have to go home by 9pm to work on a Saturday can be a little awkward. And with close partners and family, being open and transparent about my setup is a necessary conversation to have. I no longer have “free days” or weekends to do recreational things in the same way most people would assume, so I also have to manage my own expectations of what I can do when living and being with others that I love and want to spend time with. It will always be a negotiation to exist with others. And of course, I have workdays where I don’t work due to laziness or sickness (”sick days”) and days where I work on my rest day due to deadlines, external obligations, or just plain desire. I think the takeaway is to have a firm understanding of where I am, what my intentions and desires are, and communicating them with others in a way that allows us to find common ground to live in harmony together.
For the past year or so, I’ve turned my ears to the underwater rumblings, industrial gnashings, and overhead zoomings that make up the sonic environment surrounding the Newtown Creek, a body of water that separates Brooklyn and Queens and is one of the most polluted Superfund sites in the country. The creek is infamously known for the Greenpoint Oil Spill, where somewhere around 17 to 30 million gallons of oil and petroleum products seeped into the creekbed over the span of decades, only to be discovered by a Coast Guard patrol helicopter in 1978. Since being designated a federal Superfund site in 2010, many environmental remediation projects in the area aim to clean the water and surrounding ecosystem. Still, the area remains environmentally compromised due to industrialization, continued oil pollution from nearby refineries, combined sewage overflow events that regularly dump human waste into the creek, and toxic runoff from cars and trucks that drive across the busy streets, bridges, and highways that pass over and through the area.


Despite this, the area piques my curiosity as both a harbinger of the climate crisis at our doorsteps and also as a potential stage for how we might learn to coexist with such a present-future. Sonically I’m drawn to the whooshing of cars that pass above on the Long Island Expressway, the stochastic bubbling of aeration systems meant to re-oxygenate the murky waters, and the resilient wildlife that still makes this once vibrant marshland home. If you’re lucky you may catch a glimpse of a stray egret searching for food among patches of sawgrass planted by ecological restoration projects. Crabs, jellyfish, and the occasional seal still swim below the creek’s still surface. Closer to the nearby Fedex distribution facility, cacophonous calls of birds suggest an area that isn’t so devoid of wildlife after all.

That is, until you realize that these bird calls are not made by living creatures. Rather, they’re a mix of artificial, pre-recorded birds that are meant to keep actual birds away from the inside of the distribution facility so they won’t nest or cause any unnecessary disruption to the continual churn of capitalism and industry. Having heard these calls, I was left wondering: What birds are these calls meant to be? (World-renowned birder Laura Erickson believes they might be American Robin or European Blackbird and some kestrels.) More interestingly, what birds were these calls meant to keep away? Are those “pest” birds even around anymore? If not, are these artificial bird calls singing out to phantom birds that no longer exist?
Curious about the poetic implications of these "Birds of FedEx,” and in keeping with my desire to learn more about audio machine learning during my time at the Recurse Center, I set out to make a bird sound classifier that could be used to identify birds in the Newtown Creek based on their calls. I had built an environmental sound classifier before, so the project was meant to get me more experience with audio scene classification. I was also interested in how identifying bird species could be useful for environmental remediation projects that require identifying and maintaining counts of animal species across a wide area—something that microphone arrays and sensors networks make possible. Finally, for my own creative and artistic investigations, I thought the idea of a bird sound classifier could help in my acoustic explorations of the Newtown Creek.

I started by finding a suitable bird sound dataset to train on. The largest and most comprehensive one I could find was the BirdCLEF dataset, which comprises over 36,000 recordings of bird calls across 1,500 species native to Central and South America. Based on the work done in the BirdCLEF baseline system, I was able to organize the recordings into folders named after each of the bird species to be later used for classification training.

The next big hurdle was finding the bird calls in the recordings. Each recording lasts a few seconds to a few minutes, with no documentation of where in the recording the bird calls are (this is known as a weak-label problem, common in audio event classification where the onset and offset times of the event in question are unknown). I wrote code to scan through each of the recordings and cut them into one-second segments. From there, I applied a short-time Fourier transform on each segment to generate a spectrogram. Then, by using a heuristic, I was able to determine whether or not a segment contains a “chrip” (which I assumed to be a viable bird call). From there, I saved each spectrogram in a folder named after the corresponding bird species. The result was thousands of bird call spectrograms, nested inside their respective bird species folder, which I used for training a neural network. This animated GIF shows spectrograms generated for the Golden-Capped Parakeet (Aratinga auricapillus).

After preprocessing all of this audio data, the only thing left to do was to train a neural network to classify the bird calls. I opted to use fast.ai, a wonderful library that serves as a easy-to-use API on top of PyTorch, and does a lot of the boilerplate work for you in setting up and training a neural network. Since I was going to be training on spectrograms (images that represent the frequency content of a signal), I used a convolutional neural network pretrained on ImageNet. I used a technique known as transfer learning, which reuses most of a pre-trained network that’s already able to recognize visual patterns like curves and edges. The spectrogram training data was only used to “fine-tune” the last layer of the network. After many hours of training, the neural network was able to recognize bird calls from my validation set to an acceptable accuracy, validating this project and idea.


The work continues to this day, and I’m working to find more bird call field recordings specific to the Newtown Creek to use as training data for my network. I also collaborated with artist Kelly Heaton to use my classifier for categorizing bird-like sounds made by her electronic bird sculptures. I’m still out and about the Newtown Creek these days, so if you see someone, ears covered by headphones and microphone in hand, call out a hoot. I might turn and look in your direction, hoping to hear new and exciting things happening in the area.
This was my last week in batch at the Recurse Center, and what an experience this has been :). I'm so thankful for the community and what we were able to do these past two weeks in making remote RC work so well. I'm grateful for everyone at RC, including the faculity, everyone in batch, and the supportive alumni community. As we say here, we "never graduate", so this isn't the end of my time at RC, just the end of a long beginning on-boarding process into the RC community.
I spent most of my programming time this week working on my real-time audio classifier mobile app in Expo/React Native. I spent most of my time trying to understand the capabilities of Expo's expo-av library. Audio data isn't easily accessbile, so I had to figure out how to save an audio file, and load it back as binary data. I was able to get that far, and wanted to try drawing the audio signal to the screen. Unfortunately I had a lot of difficulty with this, due to the fact that most documentation I came across doesn't use stateless functional components, so I had trouble converting those examples to this more modern React Native paradigm.
Here are some drawing/2d canvas references I came across:
Canvas drawing in React Native:
https://blog.expo.io/introducing-the-canvas-2d-context-api-for-expo-8ba6106ed8e5 https://github.com/expo/expo-2d-context https://github.com/iddan/react-native-canvas https://github.com/expo/expo-three https://github.com/expo/expo-processing
I also did to some work getting my JS development environment set up (installing ctags /JS plugins for vim) so I could code a bit more comfortably.
Ctags / JS development:
https://medium.com/trabe/navigate-es6-projects-with-vim-using-ctags-948d114b94f3 https://www.gmarik.info/blog/2010/ctags-on-OSX/ https://github.com/romainl/ctags-patterns-for-javascript https://www.reddit.com/r/vim/comments/8i8rwp/what_plugins_do_you_use_for_developing_in_jsreact/
This was also my last week watching video lecture's for MIT's 6.006 couse, Introduction to Algorithms! It was such a solid class, I highly recommend it. I'm looking forward to studying more during my time at Pioneer Works, now with this foundational material under my belt :)
Alas, this is my last write up for my time at RC. Its been real! I'm looking forward to staying involved with the RC community. Never graduate!
This was our first week of Remote RC. I spent most of the week adjusting to this new normal, trying to create some positive habits while working from home (still getting up at 7am and going for a bike ride, stopping work around 7pm). There were some highs and lows this week - I think everything is day-to-day right now. All said, I did accomplish a few good things this week.
I made some progress on Whisp v2, and I'm at a point now where I can finally get audio data out of Expo's AV library (albeit kind of crudely). Hopefully by the end of next week I can show of something intesting like doing a STFT with that data. Follow along on the Whisp app repo.
Here are some links on some on-going research on getting audio data in Expo/React Native:
Research on Whisp V2: Building an instrument tuner
Otherwise this week I started up fastai's 4th version of Deep Learning for Coders, while working on finishing up part 2 of their previous version. I'm kind of behind but trying to keep up!
This week I also watched more of MIT's 6.006 - mostly on Dynamic Programming this week. A lot of it I think will only make sense with practice, so I'm excited to start doing more dynamic programming problems and go back to these videos as reference in the future.
Next week is my last week at RC :( I'm hoping to just keep coding and working on my projects up until the last day. Maybe I'll try streaming in Twitch? Heh. We'll see. By next week I hope to 1) Finish 6.006 lecture! 2) Be caught up on Fastai lessons 3) Have STFT working in JS
Whew. Quite a week. With all the news and everything going on with the global pandemic, its been a bit of an unproductive, chaotic week. I do want to just write at least something about what I did, just to keep these posts going...
This week I have been extending my work on Flights of Fancy in collaboration with Kelly Heaton to take a recording of her electronic bird sculpture and run it through my bird sound classifier to see what bird specieies it predicts.
The work is now up online here: Deep Fake Birdsong
We started by taking a recording of Kelly's electronic bird sculptures:
Then I used my Flights of Fancy software to extract spetrograms from that recording, and ran them against my classifier to see what birds it predicts these sounds came from. Here are some results:
We also produced a bar chart showing the amount of of times a speicies was detected over the 122 segments.
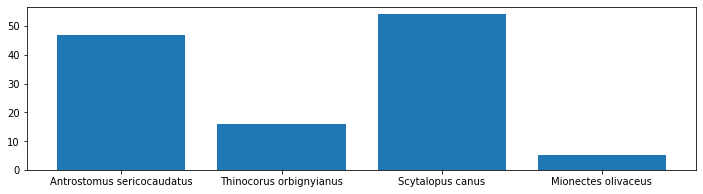
We submitted thr project to Ars Electronica, Hackaday, and Project 61. We'll see how this project develops!
Otherwise, I didn't get much else done programming wise. I did do my first competitive coding contest though! I got one right 8-)
I also started two new study groups at Recurse Center - one on Computational Audio and one on Machine Learning.
For the Computational Audio Study Group, one RC member showed off how to build an in-browser turner, and another showed off this neat in-browesr DSP language called SOUL.
For the Machine Learning Study Group, we are all collectively reading a paper on Independent Component Analysis, and I'm individually going to read about Autopool.
With that, for next week I plan on continuing on with 6.006, fastai lessons, implmenting STFT in JS/React Native for the Computational Audio Study Group, and doing some more audio ML/reading of papers for the Machine Learning Study Group.
This week started out with a continuation of last week's Un/Sounding the Relational City conference. On Monday I got to see a wonderful talk put on by Cathy Van Eck, and then in the evening there was a performance by Jenn Grossman, Viola Yip, Cathy Van Eck, and Keiko Uenishi.

Back at RC, I started working back on my real-time audio classifier mobile app. One of the things I need to work on is generating spectrograms in my app. I opted to use React Native in order to have it work cross-platform, so for now I'm working on implementing some essential DSP algorithms in Javascript (which is not really a programming language I use often or feel very proficient in). I'm hoping just by doing this project I'll get a lot better at DSP, Javascript, Reactive Native, and eventually doing real-time audio ML on embedded/mobile devices. Quite a tall order / high mountain to climb, but I know its going to feel great once I get there :)
For now I'm researching how to perform the FFT in Javascript. Here are some of my current research notes:
DFT in Python from the ASPMA course
FFT as implemented in librosa (which essentially uses numpy's fft module)
Nayuki's post on how to implement the DFT
Nayuki's post on how to implement the FFT
3brown1blue's visual introduction to the Fourier transform
Intuitive Understanding of the Fourier Transform and FFTs
I didn't get very far with it this week, but having done some initial research I feel good about moving forward with it more next week (especially now with more free time now that ASPMA is done!)
On the audio ML front, I've gotten back in touch with the fastai audio library team and I'm looking forward to contributing to something starting next week. For now, I put my bird sound classifier up on Github, to share with others: Flights of Fancy
As always, I kept up with 6.006 again this week as well as the fastai pt 2 video lectures. Looking forward to continuing that work next week!
This week felt like more of a continuation of last week. Instead of much coding, I was coming down from my talk at the Experiential Music Hackathon, and spent most of my time/mental energy on my talk for Localhost and my performance at the Un/Sounding the Relational City conference - both of which went really well!
Batch of spectrograms generated from calls of the Golden-capped Parakeet, found in Brazil and Paraguay and currently threatened by habitat loss
This week felt like the first time in a long time where I could take a breath and try to sit back without heads-down working. I'm going this signals a move from me being aggressively inward facing to a space where I'm a bit more loose and relaxed while at RC, open to new things and finding time to work in a more loose, less structured way. We shall see...
This week I finished the Audio Signal Processing for Music Applications course on Cousera, which was pretty amazing. I feel like I got exposed to a lot of fundamental audio signal processing concepts, as well as had the opportunity to practice them programatically. Moving forward with my real-time audio classifier, I'll definitely need to implment short-time Fourier transformations and log-mel-spectrograms, so I feel like with this course, I now have the tools to not only implement these algorithms but to deeply understand them from a theoretical point of view, as well as how and why they are used.

It also turns out that the MTG group worked on Vocaloid!
In 6.006 news, we learned about shortest path algorithms this week - from a more general point of view and with Dijkstra's algorithm.
What I thought was a beautiful diagram about graphs
Using starcraft early game / rushing build order as an example shortest path problem
My plan for the following week is to bring my real-time audio classifier app back to the fore front and use all the programming I learned in ASPMA to help implement any of the audio signal processing I come across to finish the project.
This week saw a lot less coding and a lot more synthesizing. I spent most of my week preparing two talks that I will be giving.
The first is at the Experimental Music Hackathon.

At this event, I'm going to be talking about how attuning our hearing to environmental sounds can inspire new ways of music making.
The second talk is at Localhost, a series of monthly technical talks in NYC, open to the public, and given by members of the Recurse Center community. I will talk about using fastai’s new audio library to train a neural network to recognize bird sounds around the Newtown Creek, an ecologically compromised estuary between Brooklyn and Queens.
I was able to clean my notebook up to show off how training works, from getting the dataset to performing inference! It should end up being a pretty great presentation :)
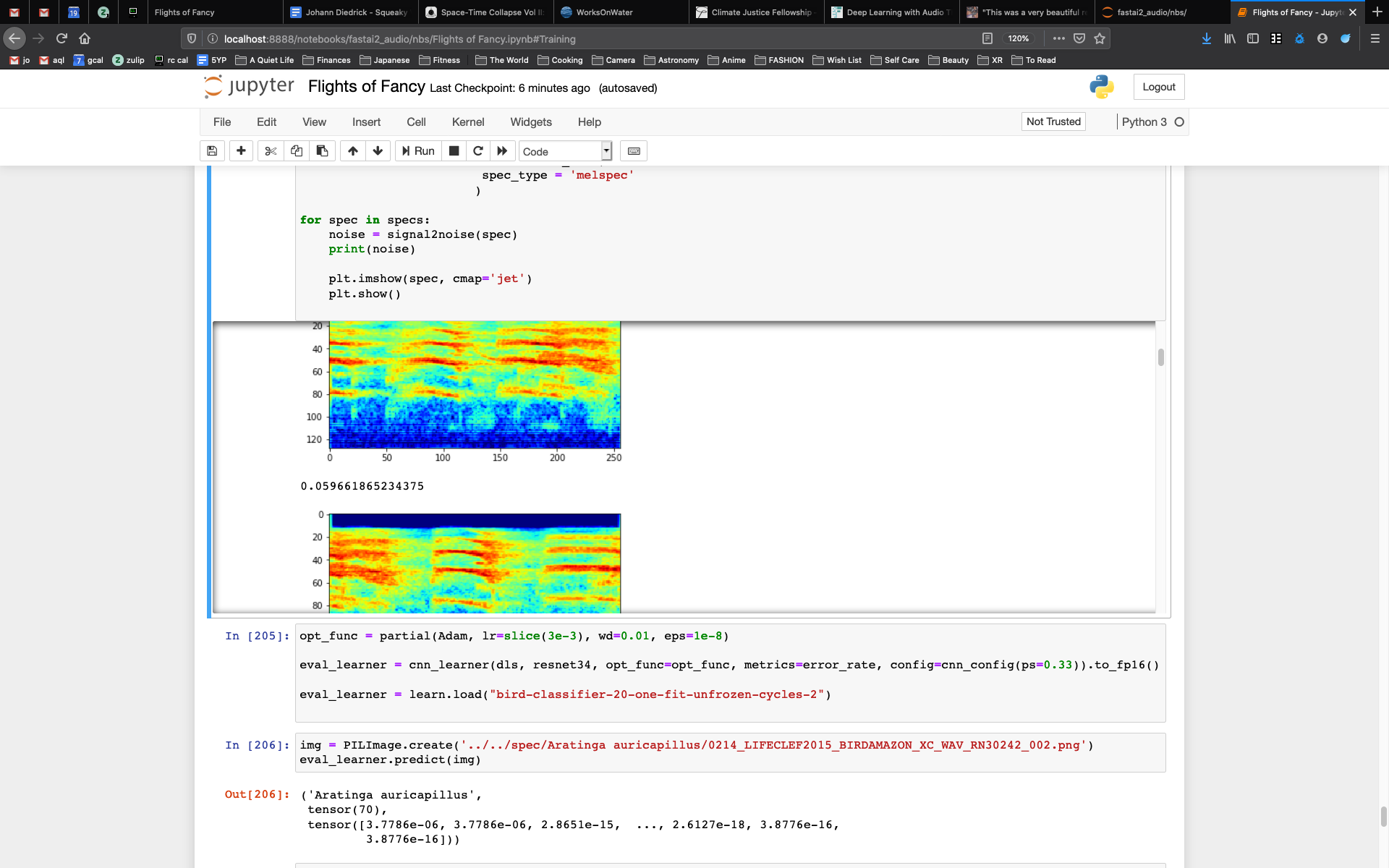
I'm also preparing for a performance at the Un/Sounding the Relational City conference at NYU, where I will be performing Cerulean Waters with Ethan Edwards.

Here is a video of us performing a version of it earlier last year at H0L0:
Because of all of that, I haven't done much coding this week. I did do a fair amount of coding to clean up my bird classifier notebook, which I'm now calling Flights of Fancy (which is also the name of my Localhost talk :D).
Otherwise, I kept up with my video lectures, watching week 9 of the fastai's deep learning course, week 9 of ASPMA, and Lecture 13 and 14 from MIT's 6.006 course.
 Cycles
Cycles
 Sound Collections
Sound Collections
 Sound Similarity
Sound Similarity
 Sound Clustering
Sound Clustering
The first half of next week should have me in the same headspace, and then starting on Tuesday I'll be back to coding: working on the fastai audio library, training more model examples, and working on my real-time audio classifer mobile app.
Hope to see you out at some of my upcoming events! ✌ 🏿
Today is the end of my sixth week at Recurse Center, and the halfway point of my 12 week batch. Its 9am, and I'm sitting here by myself on the 5th floor, feeling exhausted but in a good way, tired yet full of energy, unsure about how I feel about the week but knowing that I've accomplished a lot and still have an equivalent amount of time left to push myself to do more.
This week I finished week 8 of ASPMA, which was really interesting and was actally the kind of material I was hoping to learn. We learned about sound transformations, and how we could take a lot of the fundamental ideas and models from previous weeks (short-time Fourier transformations and the harmomic plus residual / stochastic model) in order to make some really compelling transforms. Here are some screenshots of some of them.
![]()
![]()
![]()
![]()
![]()
I'm looking forward to taking some of these techniques with me to Pioneer Works in and seeing how I can incorporate them when generating new soundscapes.
I also finished Part 1 of the fastai Deep Learning course for a second time! It was great getting a second pass at the material, as it really does require multiple viewings because of the density. Something I noted to look into is how to use (W)GANs to create new soundscapes from (environmental/industrial) noise. I think there is a lot of rich material here, especially in thinking about the poetics of taking enviromnetal "noise" and turning it into a more "desirable" state. I'm really excited to now know about some approaches that I can play with at Pioneer Works!
One of my goals for the week was to build out a prototype of a mobile app that shows your camera view, and also lets you record and playback audio. I'm happy that I was able to achieve that goal this week! Using Expo, I was able to get the camera view up and running in no time.
With the help of another Recurser, we were able to take Expo's audio recording example and refactor it to work in my current app.

I'm not sure specifically where to go next with this (maybe making spectrograms on the phone?), but I feel like this was a great first step and gives me confidence in moving forward with this project.
I hit a plateau with my bird sound classifier this week and kind of stalled out on it... I spent most of the week training, and tried running a 20+ hour training job overnight that ended up not completing. Lesson learned: If you can (and I can!) run something in a smaller, incremental number epoch cycles, do that! My sneaking suspicion, after talking with another Recurser, is that the Python process managing my training was doing a poor job managing memory, causing the RAM on Mercer (one of our GPU-enabled cluster computers) to slowly fill overtime and not get released, which in turn caused a swapdisk process on the machine to constantly go back in forth between trying to retrieve memory to and from the hard disk. I'm running my training again with a smaller amount of epochs (10 instead of 30), which I think is much safer and will always be done if I run it over night. I almost went home in defeat but took some time to do some non-coding things and felt better in the end :)
 Me going down to visit Mercer to say "You're doing a great job...keep going!!"
Me going down to visit Mercer to say "You're doing a great job...keep going!!"
 So close and yet so far...
So close and yet so far...
I think I hit a point with this project where I should try reaching out for advice on how to move forward, so I'm going to be posting my notebook to the fastai forums to see what others think. Next week I need to get my head out of the weeds, step back and tie it up at this point, in order to have a nice completed version of this project to share for my upcoming Localhost presentation.
I think my goals for next week will be tidying up my bird classifier project and demonstrating it doing inference on recordings from the dataset, and then from recordings of birds found in the Newtown Creek (ideally with my own recordings). All of this should be in the service of preparing for my Localhost talk. I think with that done, I'll be in a better place to try training models on outher audio datasets. I'd ideally like to also find time to pair with others on my mobile app, which is already at a good place. As always, I'll be continuing ASPMA, 6.006 lectures, and now Part 2 of the fastai Deep Learning lectures!
This week felt a bit chaotic, but maybe the good kind? I feel like I had a few small victories, and reached a new plateau from which I can start to look outward and see what I want to accomplish next. A local maxima, if you will.
Over the weekend I attended NEMISIG, a regional conference for music informations/audio ML at Smith College. I feel like I got a lot of good information and contacts through it, and it was a really valuable experience that I'm still unpacking.
 My kind of humor, only to be found in a liberal Northeastern small college town
My kind of humor, only to be found in a liberal Northeastern small college town
 Poster session for the conference
Poster session for the conference
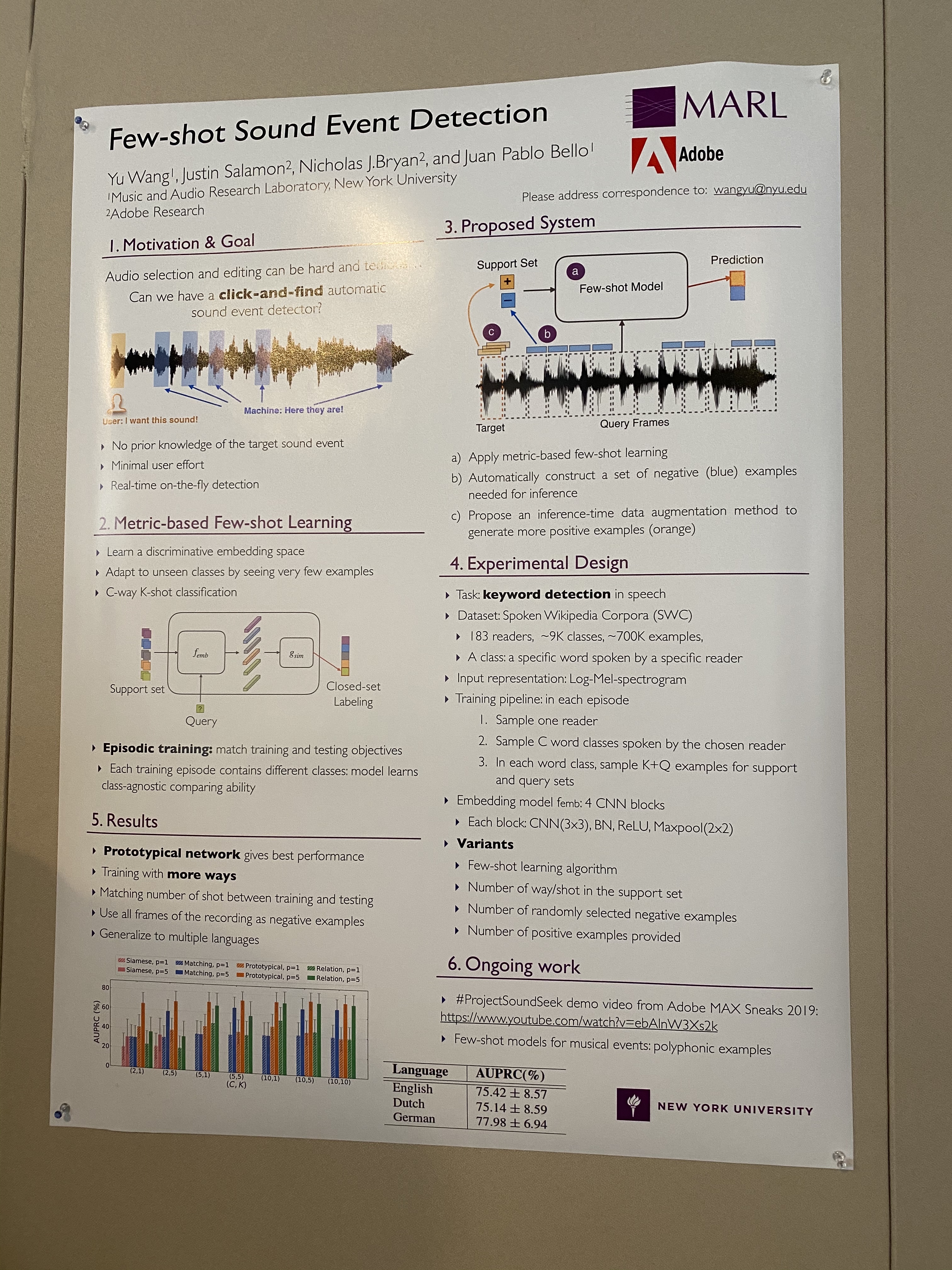 Poster on Few-shot Sound Event Detection
Poster on Few-shot Sound Event Detection
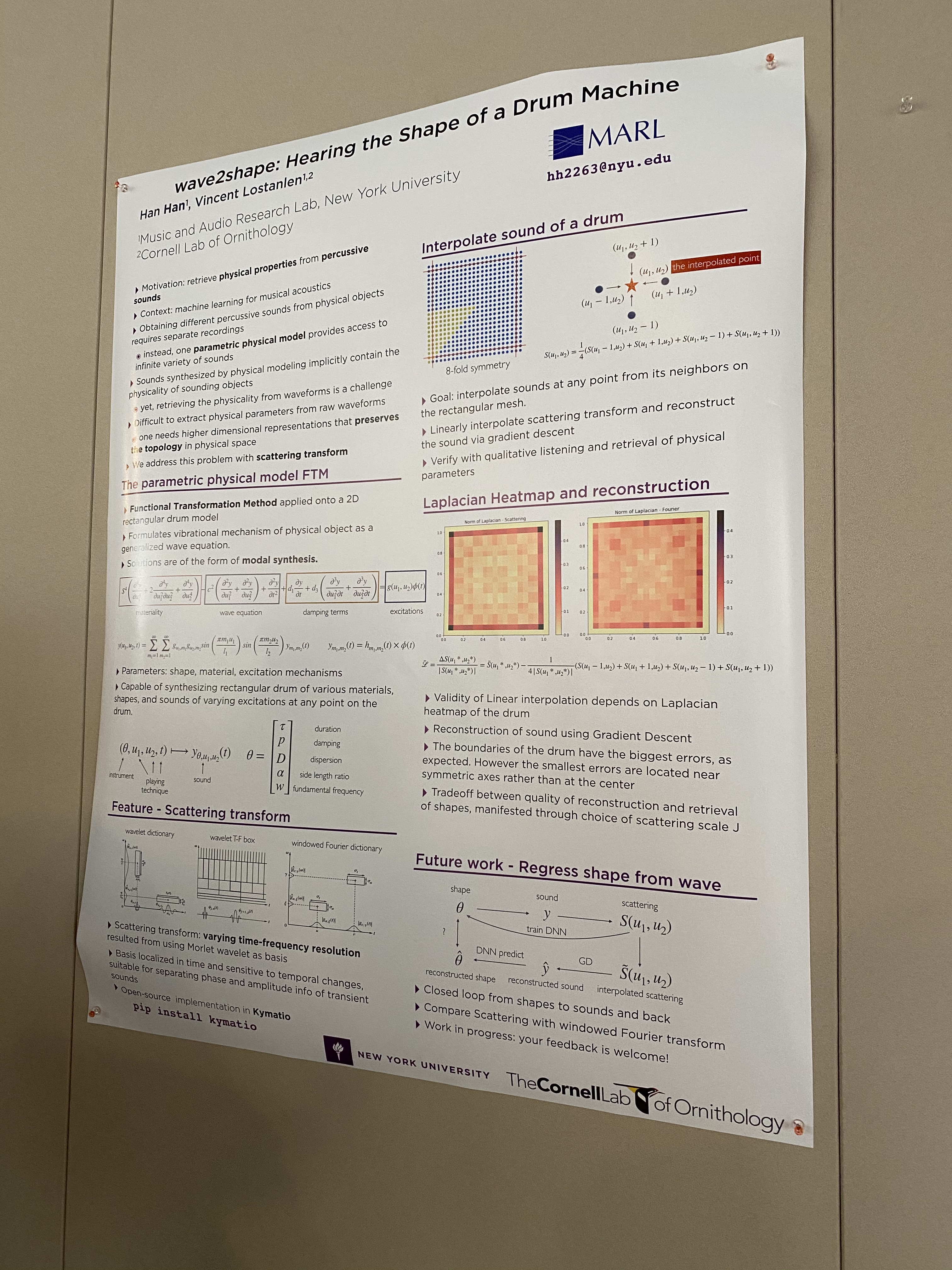 Poster on wave2shave - drum physical modeling using scatter transformations
Poster on wave2shave - drum physical modeling using scatter transformations
 Vincent Lostanlen giving us a whirlwind crash course into scatter transformations and wavelets
Vincent Lostanlen giving us a whirlwind crash course into scatter transformations and wavelets
 One of my RC conpatriots put me on to Olivier Messiaen's Catalogue d'oiseaux, relevant to my bird sound research
One of my RC conpatriots put me on to Olivier Messiaen's Catalogue d'oiseaux, relevant to my bird sound research
This week I finally got to training my bird sounds! After spending last week creating my spectrograms, I was able to move everything over from our cluster machine with the largest amount of space (broome) to a GPU-enabled machine for training (mercer). Afterwards, I looked at some of the new fastai tutorial notebooks to put together the training pipeline necessary to train with my spectrograms.
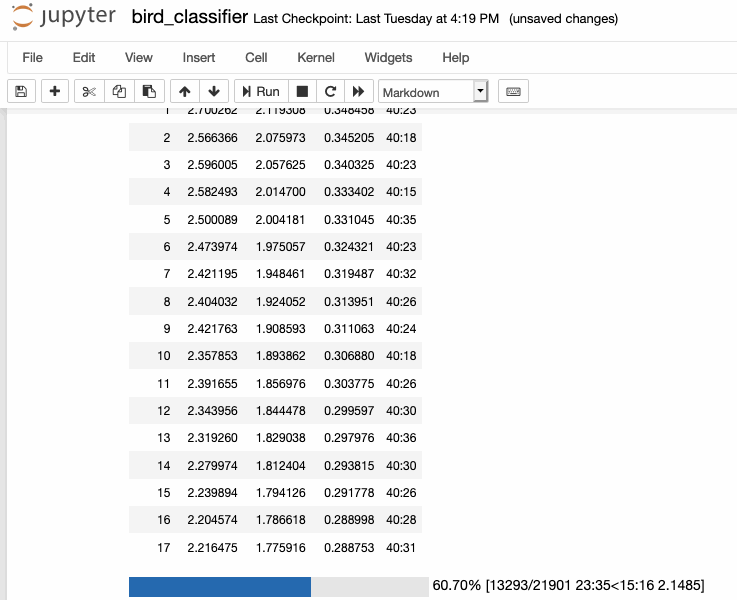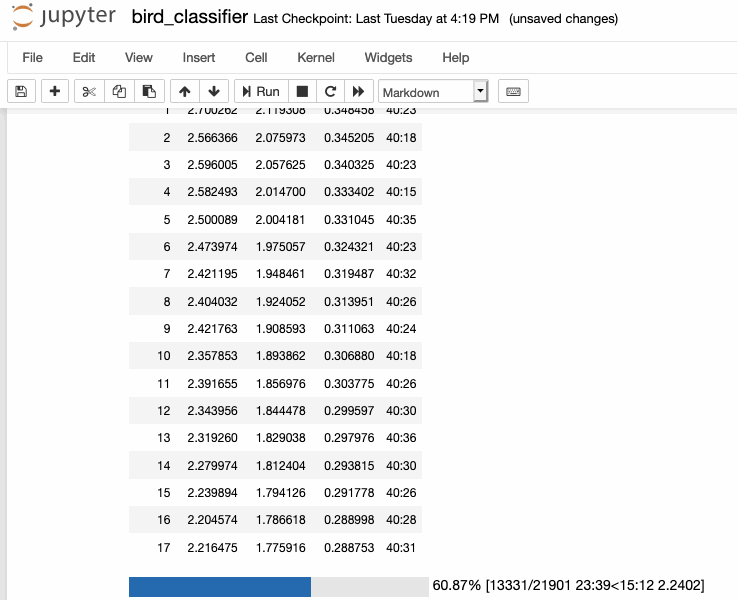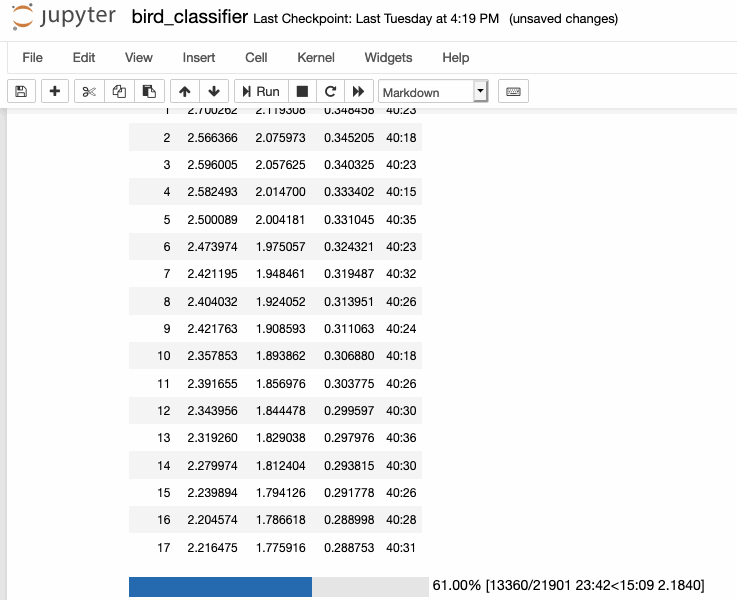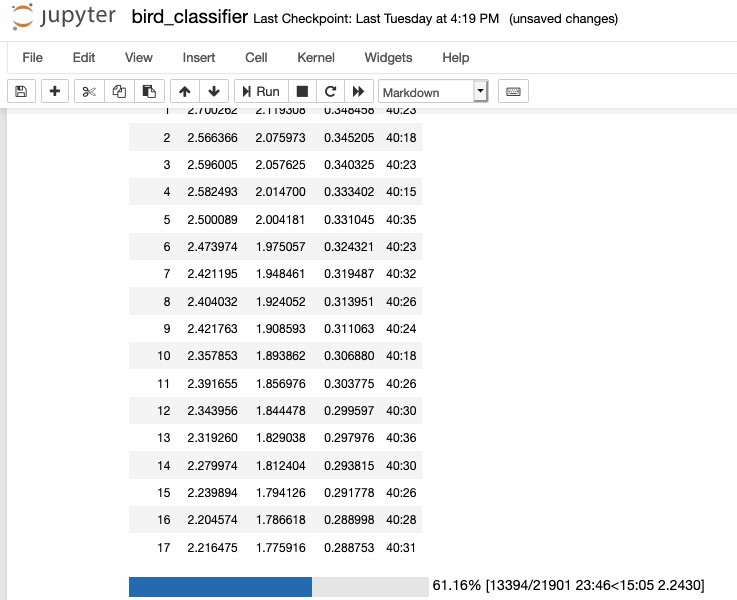
As of writing, I was able to train my model down to a <30% error rate, which is really greatcompared to the literature I read before, which was much higher (closer to 50%).
I still don't understand some of the metrics involved in some of evaluations in papers, so I'm going to dedicate sometime to understand them better in order to better understand my own training metrics. For example, the paper written about this dataset, Recognizing Birds from Sound - The 2018 BirdCLEF Baseline System, says thei "best single model achieves a multi-label MLRAP of0.535 on our full local validation set including backgroundspecies after 70 epochs". I'm not really sure how to calculate that and how that even relates to my single-label classification method, so its definitely something to dig into.
I am using transfer learning to train my dataset with a ResNet34 architecture trained on mageNet, which is definitely why I'm getting such good results. After doing some more testing, I should retrain the whole model a bit by unfreezing it, and then train it specifically on recordings of birds from the Newtown Creek. Only then will I have a classifier that will work on those specific species of birds.
Starting next week I want to train another neural network based on the Freesound General-Purpose Audio Tagging Challenge on Kaggle, which uses the FSDKaggle2018 dataset found on Zenodo. In doing all of this, I think its going to be important to figure out a good way to pick out relevant parts of audio signals for training. This goes back to the "eventness" paper I was talking about in my last post, and as I see that weakly labeled data is a perennial problem in audio classification taks, it might end up being an area that I can focus on and try to offer some novel solutions.
All of this work is helping lead me to making my real-time audio classifier mobile app, which I started whiteboarding this week.
 Whiteboarding a real-time audio classifier
Whiteboarding a real-time audio classifier
Next week I want to do some preliminary research and maybe just get something deployed on my phone that shows the camera feed, with it maybe recording and playing back sound just to make sure that works. That would be a really good first step! I want to reach out to MARL at NYU because I know I saw a real-time classification demo they made with their SONYC project. It would be nice to get some insights from them on how to tackle this problem, and what challenges I might face along the way.
I also finished up Week 7 of ASPMA, where we looked at different models for analyzing and reconstructing residual parts of a signal not captured by the sinusoid/harmonic model, speficially with a stochastic model. It was pretty interesting and it has been nice seeing how all of these transformations and models are coming together to allow us to do some pretty sophistaced stuff.
 Harmonic plus residual analysis
Harmonic plus residual analysis
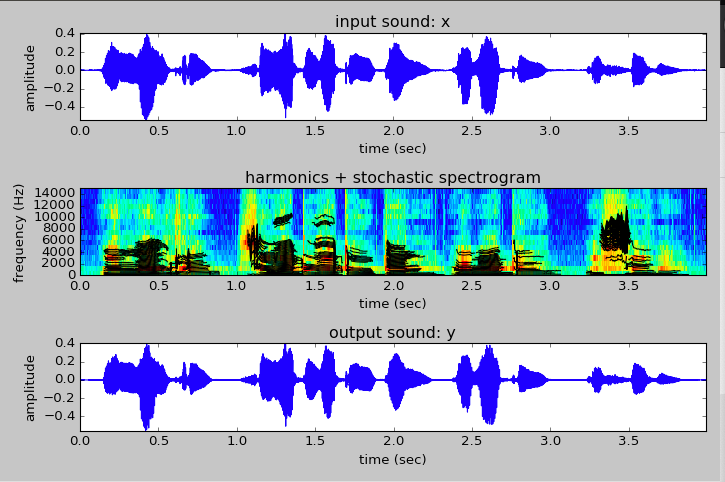 Harmonic plus stochastic analysis
Harmonic plus stochastic analysis
 Doing some short-time Fourier transform analysis on a vibraphone sample
Doing some short-time Fourier transform analysis on a vibraphone sample
I had some breakthroughs with algorithm questons, specially around binary trees. For the Algorithm Study Group, I presented a way to solve the question of finding the maximum depth of a binary tree in a way that could be used as a template for solving other binary tree problems. It felt nice to feel like I was making some progress around the topic!
 My 9am morning routine, watching MIT 6.006 lectures
My 9am morning routine, watching MIT 6.006 lectures
 Me whiteboarding out a solution to finding the maximum depth of a binary tree
Me whiteboarding out a solution to finding the maximum depth of a binary tree
 Me presenting my solution to the Algorithms Study Group
Me presenting my solution to the Algorithms Study Group
This week at RC I focused on preparing by bird sound dataset for traning next week. I decided to go with the LifeCLEF 2017 dataset, which "contains 36,496 recordings covering 1500 species of central and south America (the largest bioacoustic dataset in the literature)". Much of my week was spend reimplementing a spectrogram generation pipeline from the BirdCLEF baseline system, which used this same dataset.
The pipeline goes through all the 1500 classes of bird species, and for each recording, the piplelne creates one second spectrograms across the entire recording (with a 0.25 second overlap between each generated spectrogram). From these spectrograms, a signal-to-noise ratio is produced to determine whether or not the spectrogram contains a meaningful signal that we use to determine if it contains a bird vocalization of that species.
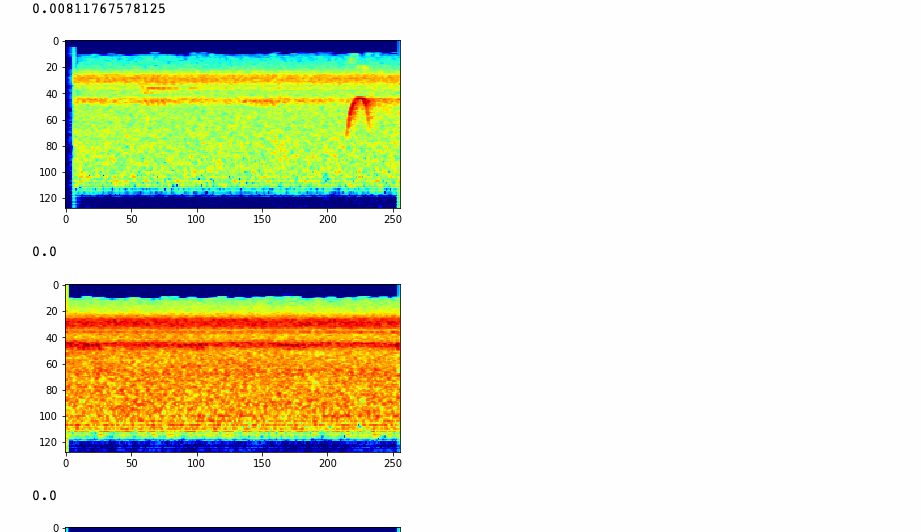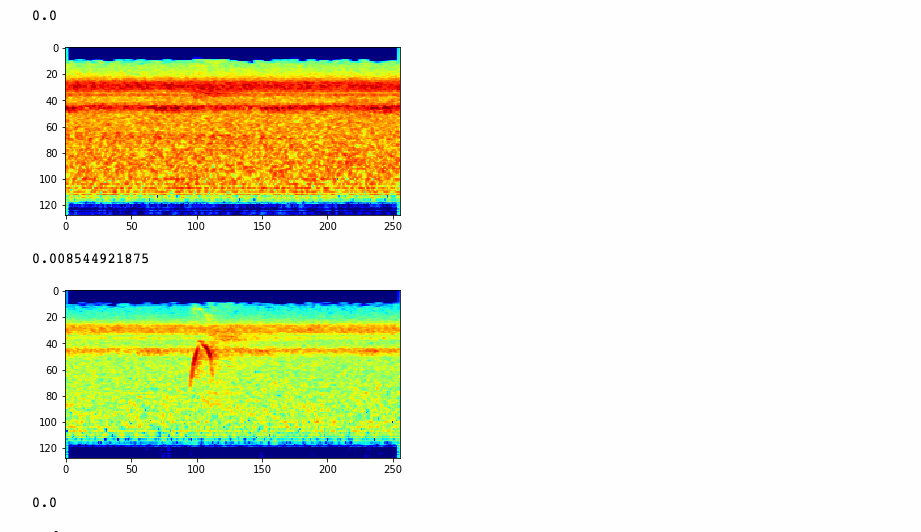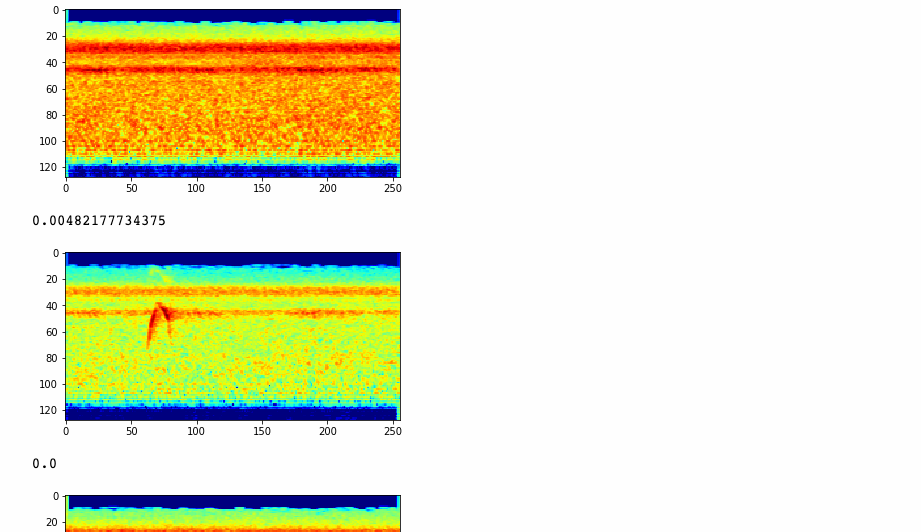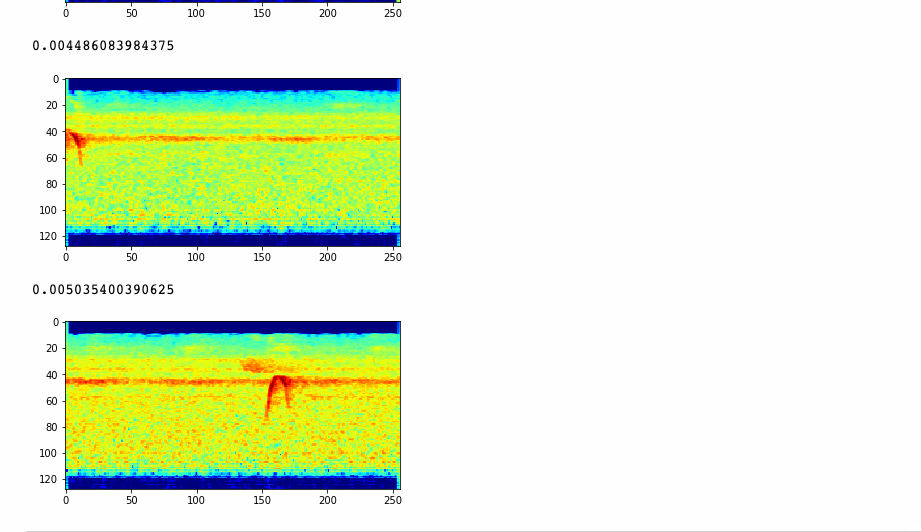
If the signal-to-noise ratio is above a certain threshold, we save that spectrogram in a folder for that bird species. If not, we save that noise-y spectrogram to be usedlater for generalizing during training.
This whole process takes an estimated six hours to run, and it results in about 50,000+ spectrograms across the 1500 classes of bird species.
My intuitive feeling about this process is that it is a bit heavy-handed, suseptible to inaccuracy, and not very efficient. However, I can understand the approach and ultimately it does get the job done. I do think this paper on Eventness (a concept for audio event detection that used the idea of "objectness" from computer vision and applies that to detecting audio events in spectrograms) proposes a more nuanced way to pull out meaningful sonic "events" in a recording. It might be something worth incorporating in another pass on this system.
I'm happy I achieved my goal for the week of generating the spectrograms from the recordings! I have been full of doubts though of how this fits into my larger goals. I think this week I fofocused on the "trees" and not the "forest", so to speak, and maybe what I'm feeling is getting a bit lost in the forest. With most of the data processing out of the way, I'm xcited to pull out a bit and think more about the context of what I'm working on and how it fits into my overall goals.
For instance, generating all of these spectrograms with this pipeline has moved me way from contributing to the fastai audio library. If I had wanted to keep down that path, I would have had to really work to not cut up the spectrograms in the way that I did, and instead come up with a way to generate the onset/offset times of the bird vocalizations from each recording and do the on-the-fly spectrogram generation with the built-in fasai audio library tools. I think that doing the actual learning task is what I want to be focusing on though, so maybe that makes it ok that I reimplemented another way of doing it, because it serves my end goal of diving deeper into the learning part of classification (it is something I would love to go back and dig deeper into though).
With that observation in mind, I think that focusing on training a neural network on these bird vocalization spectrograms next week will get me back into contributing to the library and focusing on the things I want to learn. I don't think this particular bird classification project will lead me to fixing the batch display issue, for example. I think that's okay, and maybe it will just be something I circle back to later on when trying to do other classification tasks with the other datasets I'm interested in.
I think going back to my larger goals at RC, I want to create a real-time sound classification application that can be used to classify different kinds of sounds. I've made a model for environmental sounds, and now I'm tackling bird vocalizations. I want to look at other environmental sound datasets, and if I have the time, I want to do speech as well. I think having this app as a "wrapper" application that lets you do, in general, real-time classification with any model you import will give me the room to d training on many different datasets, giving me more opportunities to dig into fastai v2, the audio library, convolutional neural networks, real-time on-device machine learning, short-time Fourier transforms, and classification in general.
So for now, my goals are to finish up the bird classification system, get it on device, and then make more models to get better at using deep learning for sound classification and understanding what it takse to do real-time on device machine learning.
Hello again. Its been really nice taking the time on Fridays to try to write and collect my thoughts on what I've been doing over the course of the week, looking back on the previous weeks, and looking forward into the future.
At the end of last week, I spent some time trying to diagram, to my understanding, the world of audio ML. Here's a photo of what I whiteboarded:

What I started to realize is that the field of audio ML has two distinct "sides": analysis and synthesis. This shouldn't be too surpiring to me. In my Audio Signal Processing class, we're always talking about analysis first, and then synthesis (which is usually the inverse of the analysis process).
This lead me to thinking that what how I should spend my time at RC. Maybe I should spend my first six weeks deeply working on analysis, which in this case would be classification tasks. Then, I could spend my last six weeks looking at synthesis, which would be the task of genrating sounds. This was what I was thinking about doing before coming to RC, and this approach seemed like a good way to see the entire field of audio ML.
I was worried though. Would I actually come out with something subtantial if I split my time like this? My larger goal at RC was to become a dramatically better programmer, and I began to think that maybe becoming more of an expert at one side of the coin would actually prove to be a better use of my time here.
The answer I came to was also driven by the fact that I would be a resident at Pioneer Works right after my time at RC, so I would be spending an addtional 12 weeks somewhere else where I could be more "creative" and "artistic" in my approach. So, that lead me to decide (for now) that I would dedicate the rest of my time at RC fully and deeply understanding the analysis side of audio ML, and build out a tool kit for real-time audio classification that I could use in the field. Yay!
With that in mind, I'm continuing my investigation into bird sound classification, with the intention of making a real-time audio classification app that lets you identify birds in the field, along with other environmental sounds (which would end up being an upgrade to my Whisp app), and speech as well. I don't necessarly have to get to all of these things at RC, but I can build out the scaffolding/framework to do this, and use bird sounds as my first, deeply investigated dataset. I think I will also have the time to fold in environmental sounds as well, as its something I've done before, and maybe even sneak in speech as a stretch goal.
All of this is being facilitated with my involvement with fastai's audio library. I'm proud to say that my first pull request was merged into the library this week! This makes for my first open source contribution :D
I had a lot of great conversations with people in the audio ML space this week, including Yotam Mann and Vincent Lostanlen. Both have been super supportive in my work and have made themselves available to help out where they can. In particular, Vincent pointed me to a lot of great research around bird sound classification, including BirdNet. I wasn't able to find their dataset, but it lead me to the BirdCLEF dataset. Vincent said it was weakly labeled, with no onset/offset times for the bird sounds, so it might require a lot of work to get going. We shall see!
Otherwise, this week was also good for my Audio Signal Processing class. We learned about the Sinusoid model and how to do things like spectral peak finding, sine tracking, and additive synthesis.
In algorithms, a lot of time this week was spent on trees, including binary trees, binary search trees, and self-balancing trees like AVL trees. In the Algorithms Study Group we also spend a lot of time looking at Floyd's cycle finding algorithm, quicksort, and graph traversal algorithms like depth-first search, breadth-first search, and Dijkstra's shortest path finding algorithm.
Week 2: Noise to Signal
Hello! This week I really felt like I made a lot of progress towards my goals. A lot of things came together in a really great way, and I can start to see how my overall approach to RC and what I'm studying is informing each other and interleaving in ways that I wanted it to.
This week I started by getting a lot of video lectures out of the way on Sunday, including the week 4 of fastai's deep learning course and ASPMA. That really set me up well to focus on programming for most of the week, instead of burning most of my time with lectures and fueling my anxiety that I'm not programming/making enough.
I also decided this week to try not to context switch as much - for now, I'm trying to still spend the mornings working on algorithms, but now I'll alternate days where I focus one day on ASPMA/audio signal processing and the other day on audio ML/fastai. I think it worked out really well this week, and made me feel less anxious to rush through something so I could switch to another related but contextually different tasks. So for this week I did ASPMA work on Monday and Wednesday, and audo ML work on Tuesday and Thursday. I found it successful, so I'm going to try it again next week!
This week I feel like I made a lot of progress in the audio ML front, combining some of the stuff I've been learning about in the ASPMA course into the work I've been doing with fastai's new audio library. In the ASPMA course, we learned about short-time Fourier transform and how its used to generate spectrograms. I was able to use some of that knowledge to try to make a real-time spectrogram generator from the microphone. It didn't turn out super well, and its something I want to master, so I think I'll take another crack at it next week.
Earlier in the week, I met with Marko Stamenovic, an RC alum who works professionally on audio ML at Bose. We had an amazing conversation about audio ML, some of the current topics in the field, areas to check out related to my interests, and what it would be like to work professionally in that field.
We talked about a lot of topics that I need to go back and check out, including:
For audio generation, Marko pointed me to: - WaveNet (DeepMind) - FFT Net (Adobe, Justin Saloman) - LPCNet (Mozilla)
He suggested first trying to genrate sine waves, then speech, then field recordings with these architectures.
Marko also told me to really focus on the STFT as its a fundamental algorithm in audio ML. He also mentioned that being able to do deployed real-time audo ML on the phone is very in-demand so that might be something I try to refocus on while at RC.
This week I was also able to finish my PR on fastai's audio library. The task at hand was creating a test to make sure spectrograms generated with the library always returned right-side up. I was able to use some of the skills I learned in the ASPMA class, specifically around generating an audio signal, in order to create a test case to create a simple 5hz signal, generate a spectrogram from that, and test to make sure the highest energy bin in that specgrogram was at the bottom. This was such a great moment where everything felt like it came together, and I only imagine that this will happen more and more :)
Finally, I did more MIT 6.006 lectures on algorithms. This week was sorting, including insertion sort, merge sort and heap sort. I particularly love heap sort! I also gave a small presentation on merge sort at RC as part of our Algorithms Study Group, which forced me to really dig into merge sort and understand how it works, including writing out its recursion tree. I love forcing myself into situations that make it guarenteed that I'll have to really focus and deeply understand something so that I can present it to others. I hope to do it more in the future.
For now, I think everything is moving well. I do want to realign what I'm working towards, and try to keep the bigger goals in mind of making something that generates sound. I do think though that the listening part of this is just as important, so I want to think about how to combine the two, because I do think they are both two sides of the same coin. I'll spend a bit more time thinking about that today and I'll hopefully have some idea forward before setting my goals for next week.
Hello! If you are reading this, welcome! This is my attempt to be a better (technical) writer, starting with writing about my programming life at the Recurse Center. For more about me, please visit my personal website. For a quick intro, I make installations, performances, and sculptures that let you explore the world through your ears. I surface the vibratory histories of past interactions inscribed in material and embedded in space, peeling back sonic layers to reveal hidden memories and untold stories. I share my tools and techniques with others through listening tours, workshops, and open source hardware/software. During my time at RC, I want to dive deep into the world of machine listening, computational audio, and programamtic sound. To do that, I'm splitting my time, 2/3s of which will be spent on audio ML and audio signal processing. The other 1/3 of my time will be spent on getting a better foundation on computer science, algorithms, and data structures. In the following post, I'll write about my experience with those areas, and pepper in some observations along the way that I've had since being here!
On the audio ML side of things, this week I dove into fastai's new version 2 of their library, specifically so I could start working on their new audio extension! I'm really excited to contirbute to this extension, as this will be the first time I've really contributed to open source. The current team seems incredibly nice and smart, so I'm really looking forward to working with them. The first thing I did was get version 2 of fastai and fastcore setup on my Paperspace machine, but then I realized that I could/should get it set up on RC's Heap cluster! This took a bit to get working, but it was pretty smooth to get everything setup, so now I feel ready to start working with it. My first project idea was to build a bird classifier, using examples of birds found around the Newtown Creek. I was able to put together a test dataset from recordings I downloaded on https://www.xeno-canto.org/. I did want to start training this week, but I think that's going to have to happen next week. This week I also finished up to week 3 of the fastai DL lectures, so that was good progress. Next week I'll tackle week 4 and use the rest of the week to actually code something.
On the audio signal processing side of things, I was able to finish week 3 of the Audio Signal Processing for Musical Applications course on Coursera, which I've really been enjoying. Week 1 and 2's homework assignments were pretty easy and straightforward, but this week's homework assignment was way more difficult! I didn't expect it to take as much time as it did, and I did have to cut some corners at the end and look at someone else's example to finish it. It wasn't the most ideal situation, and I now know going into next week to anticipate needing to spend more time with the assignments.
Finally, on the algos side, I finished Lectures 1 and 2 of Introduction to Algorithms 6.006 from MIT Open Courseware. I tried a couple of LeetCode questions related to those lectures as well. I need to find a way to make sure I actually code things related to that course, instead of just simply watching the videos. My approach has been 1) Watch a video 2) Do a couple of problems related to that, all before lunch. I think if I can get into a good flow for this, I'll be doing just fine.
Over the course of my first week, I've already had my ups and downs. One thing has been being overambitious in what I can get done in a day. I'm ready spending 9am-7pm at RC, and I still have the feeling that I can't get everything done. I'm going to have to be ok with not getting everything done that I've set out to do each day.
I had a nice check-in with one of the faculty members about algo studying and project management. Two takeaways were: 1) Don't spend all your time at RC griding on algorithm studying/cramming videos. Do some, but don't spend the entire day doing it. And 2) Once you feel like you know enough of what you need to get started on a project, start! Let the project drive what you need to learn.
One of the things I think I should start doing is create a list of goals for the week on Sunday night, and then let that drive what I should be focusing on for the week, making sure I've planned out enough time and space during the week to realistically make those goals happen, knowing that I want to leave space for serendipity while at RC.
Going forward with RC, I made a list of projects I want to work on. I'm categorizing them as "Small/Known" (as in I already know how to do them or have an understanding of a clear path as to how to make them real, and "Big/Ambitious", as in I'm not exactly quite sure where to start and they will be take a longer time to do.
For now that list looks like:
Small / Known
Big / Ambitious
For next week, I want to:
Learn: Week 4 of fastai Week 4 of ASPMA Lecture 3 and 4 of MIT 6.006
Do: Make bird classifier Make Shepard tone sound generator More LeetCode problems
Because of the amount of audio files, this post is best experienced using Firefox!
Quiet Music, Weak Sounds

Introduction
Early one summer morning in Kyoto, I took this photo on along the banks of the Kamo River.

On the left bank, a women greeted the morning with outstretched arms. Up above, three birds circled over the water. Kyoto, already a sleepy city, was still waking up. In its stillness, all I had was the quiet of the city's early dawn around me. From that vantage point, Kyoto's deep morning silence stretched far into the horizon, up the Kamo River valley, and into the mountains hidden behind the clouds.
Since that summer in 2012 I have been searching for quiet sounds all around me. Sometimes these are literally quiet sounds — inaudible because of their low volume compared to the bigger, louder sounds around them. But often times these quiet sounds are not so quiet at all, and instead are quiet because of our relationship to them. They are sounds that we don't pay attention to. They take up less space. They are often "overheard" (analogous to "overlooked") because they are not usually sounds we focus on. They are effectively inaudible, used here in a similar way one might use the term "invisible". They are muted and minuscule, diminutive and shrunken, minor and pathetic. They have no wants and cause no trouble. They are sounds pushed off to the side and forgotten, overshadowed by the larger, familiar and more heroic sounds in the environment that people instantly recognize, are drawn towards, and quickly reference when describing a place.
Some examples of quiet sounds that I've come across include:
The reverberations of street life transduced through a hollow pole

The piercing pitching of neon signs

The rhythmic knocking inside of cross-walk buttons

The brushing of ripples against a lake's shore

The soft patterings of light February snow

Most of my work for the past five years has been shifting people's attention to those sounds, in an attempt to broaden our understanding of the world around us. Through this deeper understanding, we can create new, original, and more personal relationships to our environment through the discovery of the delicate, poetic, and ephemeral sounds around us — if only we took the time to listen.
My time in Japan, especially as an InterLab Researcher at YCAM, taught me a lot about listening in new ways, and I knew I would one day return back to Kyoto to get to deeply know the city and the sounds within.
The following year, I contacted Tetsuya Umeda, a sound artist from the Kansai area, about the possibility of doing listening tours in Kyoto to explore its sounds, and he advised me to get in touch with Social Kitchen, a community arts center in the city.
It would take a couple of years before I could find a way to work with Social Kitchen, and in 2015 I was introduced to the Asian Cultural Council, who ended up supporting my time in Kyoto through a fellowship grant.
I got in touch with Social Kitchen again in 2016, and they introduced me to Eisuke Yanagisawa as someone with whom I should collaborate with during my time in Kyoto.
Five years after I took that photo on the Kamo River, I was able to return to Kyoto and embark on a four-week long residency to explore its sounds through a series of workshops and field work research expeditions, titled Quiet Music, Weak Sounds
Before I arrived, Social Kitchen, Eisuke and I came up with the following program:
Quiet Music, Weak Sounds is a collaboration between sound artists Johann Diedrick and Eisuke Yanagisawa to discover, amplify, and share the subtle sounds in Kyoto, Japan.
Over the course of four weeks, Diedrick and Yanagisawa will explore Kyoto’s soundscape with custom microphones, amplifiers and field recorders.
Informed by their findings, the two will host a series of workshops, teaching members of the community how to build and use their own sonic investigation tools.
They will turn participants into acoustic explorers and take them on explorations of Kyoto to find, record, edit, and present their own found sounds.
Afterward they will construct Aeolian harps with the participants and introduce the harp's sounds to Kyoto’s Kamo River path.
Finally, the two will present their findings to the community at large, in the form of a talk and reception party.
After finally arriving in Kyoto in April 2017, Eisuke and I met and began our collaboration together.
Mobile Listening Kit Workshop
The first event hosted at Social Kitchen was a Mobile Listening Kit workshop. The workshop introduced participants to the world of sound art and provided techniques for making tools to create these experiences. This included the fabrication of a mobile listening kit and a contact microphone for use in installations, performances, and scientific research.

The mobile listening kits are portable amplifiers that can be used to hear quiet sounds in your environment. They consist of an input for different kinds of microphones — in the workshop we built and used contact microphones. You can adjust the volume of the input sound with a volume knob, and hear vibrations on surfaces through headphones or speakers. The kits are used to focus in on sounds that normally can't be heard because of their volume, and are designed to be portable for everyday use and exploration.
Most of the participants had never built any kind of electronic device before, and the workshop involved a lot of soldering and hands-on fabrication. It was important for me to have people actually build these kits, instead of using pre-built ones, because I think it is important to teach people how to teach themselves. Only by learning how to teach myself was I able to do and make the things I can today. I think it is critically important for artists to learn how their tools work and function, so that they can modify them for their own creative purposes.
















Field Recording Workshop
The next day, Eisuke and I hosted a field recording workshop. In this workshop we gave participants the opportunity to find and record sounds outside with their mobile listening kits, field recorders, and different kinds of microphones. We didn't give much instruction on what to listen for, except only to try to discover sounds in places where they least expected. In this way, the workshop encouraged listeners to reimagine their sonic environment by playfully exploring the world through their ears.
The workshop began with a quick lecture on how to use microphones and field recorders for recording sound.

Soon after we went to Goryou Shrine, a Shinto shrine just a short walk from Social Kitchen. We spent most of the afternoon at the shrine exploring its cracks, surfaces, and hidden spaces.







After spending two hours recording sounds, we came back and did a short lecture on editing field recordings. At the end of the workshop, participants presented their recordings to each other, which prompted lively questions and discussion.








Aeolian Harp Workshop
In the final workshop, we built Aeolian harps, a type of string instrument played by the wind.
Aeolian harps are objects of mystique because of the quality of the sound they produce and how that sound is made. They can range in look and form, but in general they look like simplified harps or guitars, with a hollow wooden body, usually with a sound hole, and a number of strings stretched across. Instead of plucking or bowing the harp, you can place it in the vicinity of a moderate, consistent gust of wind, and as the wind vibrates the strings, the harp produces a ghostly, haunting sound — seemingly out of thin air.
We were both really excited to host the workshop because we knew it would be a beautiful demonstration of how one can collaborate with the environment to produce sound, instead of treating sounds in the environment as a resource to be extracted as we had done in the two previous workshops. We knew that producing sounds from the harp would be difficult for a number of reasons, least of which would be that we didn't have any control of the wind on the day of the workshop. Conceptually this worked in our favor, because it meant that participants had to concentrate hard to produce and hear the sounds from the harp. They wouldn't be able to get the immediate satisfaction of making sounds like you would with an electric guitar, drum set, or computer. Instead, they had to be very patient and work with the environment to orient the harp in such a way that when a gust of wind blew their way, the harp would sound. Each sound was to be precious. The participants had to wait in anticipation, excitement, and yes, frustration, for each sound to come. Our hope was for them to ultimately develop a new kind of appreciation for weak, quiet sounds that can be just as fleeting as the wind.
Before starting this workshop, Eisuke and I traveled to Osaka to visit Kosuke Nakagawa, an expert at building string instruments including Aeolian harps. At his studio he showed us his instruments and walked us through how to build an Aeolian harp for our workshop.



Here is a video of our prototype in action:
Back at Social Kitchen, we built our Aeolian harps together.









When we were done, we brought their natural singing sound to the Kamo River. As expected, it was difficult to get the harps to sing. Walking around the river, we searched for the best place to find ideal wind conditions. Participants readjusted and realigned their harps in order to find the best position. In the process, they developed a consciousness around wind speed, path, and direction in the surrounding environment. And soon enough, the sounds came.







You can hear a sample of what the Aeolian harp sounded like here:
Field Work
During my last week in Kyoto, Eisuke and I were able to spend two days doing our own field work. We were both interested in quiet sounds, but from two different perspectives. I was interested in sounds that were quiet both in their actual volume and in their general level of recognition - sounds that lack audibility (analogous to visibility). Eisuke is interested both in sounds that reside outside of our human hearing range (mostly ultrasonic sounds), and sounds that also lack "hear"-ability because of how remote they are (he studies highland gong music from Vietnam). We picked two sites in the city noted for their quietness and sonic diversity.
The first place we went was already very familiar to me - the Kamo River. When we arrived, we found ropes installed over parts of the river that were designed to deter birds from eating fish that were swimming upstream to spawn during the spring season. The ropes would vibrate with the wind and cause a really deep frequency sound that we could record with our contact mics.



Here is what one of the ropes sounded like:
Eisuke made a similar recording as well:

I also recorded some sounds from the surface of the water with my mobile listening kit.
Eisuke also recorded sounds from underneath the Kamo River with his hydrophone.

We also found a nearby pipe that captured and reverberated the sounds of the river.

Eisuke was able to stick a mic in the pipe and record some of the sounds inside.

The next day we traveled to Katsura and Kamikatsura, located near the mountains northwest of central Kyoto. There we recorded the sounds of the Hankyu Line, the Katsura River and a nearby bamboo forest.

Against the fence you can hear the roaring and rumbling of passing bikes, cars and trains.
Closer to the mountains, we visited Jizo-in Temple.





In this temple, you could hear the sounds of birds in the bamboo...

and the sound of two flowers rubbing against bamboo while swaying in the wind.

Further up we recorded the sounds of a small falls near the Katsura river. I recorded some sounds with my mobile listening kit.
Eisuke recorded similar sounds from the same river with his parabolic microphone.

He also captured the sounds of the rustling bamboo...
...and these incredibly physical sounds of large bamboo shoots cracking and snapping.

Reception
In my final week in Kyoto, we hosted a reception at Social Kitchen to present our past work and our collaboration together.









At the end of the reception we did a live performance of our field recordings.
May Peace Prevail on Earth
Over the past few years, I have been documenting my explorations of weak sounds through short recordings with my mobile listening kit and photos taken with disposable cameras. That project, titled It Is Impossible To Know About Earth, So We Must Hear Her Voice In Our Own Way is still ongoing. During this residency, however, I decided to try documenting my recording situation with drawings as well. As part of the reception, I showed a selection of these drawings in a tiny exhibition titled May Peace Prevail on Earth.







Reflections
Four weeks may not sound like a lot of time for a residency, and it isn't. With that in mind, Eisuke and I designed an incredibly packed itinerary, with most of our activities happening over the course of my last two weeks.
A part of me is still deciding on whether or not it was a good idea to plan as much as I did for my time in Kyoto. On one hand, I was only going to be there for a short amount of time, so I thought it would be best to pack in as many events and activities as possible. On the other hand, I didn't have as much time to wander and explore as I wanted to. No doubt I was able to really feel like I sunk into Kyoto, but it would have been nice to have had more idle time to let my mind drift.
I also, intentionally or not, decided not to do as much material preparation for my workshops before I arrived. A lot of this was circumstantial, as I was traveling from another conference/workshop and probably couldn't have really brought all the materials I needed in the first place. Either way, one of the challenges that I set up for myself was answering the following questions:
What would it be like to be an artist in Kyoto?
Would I be able to find the materials I need to produce the kinds of work that I want?
Would I feel happy, inspired and able to live out my fullest artistic life here in this city?
I can say with confidence that I was able to pull off most of what I sent out to do during my time there.
Looking back at my time at Social Kichen, I feel like I developed more confidence in my artistic practice. I more firmly know what I like to do, and, maybe more importantly, what I don't like to do. For example, I know now that I am less interested in making works that are meant to be consumed on a screen. Instead I want to make more works that get people to stand up, move around, and interact with each other and the sounds around them. My mobile listening kits were always an extension of this desire, and the Aeolian harp workshop, which was so delightful to me, seems to be a continuation of that trajectory.
Even more so, I feel like I'm moving a bit away from sound recordings in general and more into physical sound environments that can be manipulated and played with. I'll probably still be interesting in documenting my "sonic experiences", but as my interest in drawing makes apparent, how I chose to document these experiences will constantly change and evolve.
One thing I am excited to do is improve my workshops. Having done so many now, I feel confident in facilitating them. I am already looking to improve my workshops by creating pictorial instructional guides that can be understood and enjoyed by anyone regardless of language. It would be much more time efficient and helpful if I can provide participants an instructional guide that they can go off with and use, allowing me to occasionally hop in when they need specific assistance.
One thing I am curious about working on more are self-sustained sound installations that use solar power to power speakers for amplification and natural sources of energy (wind, water) for sound activation. I am working on two new works, one for this year's Megapolis Festival and another for a group show at Little Berlin (both in Philadelphia), that have me working through these ideas and with these materials.
Acknowledgements
I would like to thank the Asian Cultural Council for their financial and institutional support.
I would also like to thank Social Kitchen, especially Sakiko Sugawa, Makato Hamagami, Asuka Okajima, Kumi Wakao, Yuh Wakao, and Shingo Yamasaki.
Finally I would like to thank my collaborator Eisuke Yanagisawa.
Thank you Mehan Jayasuriya for helping to edit this post!