For the past year or so, I’ve turned my ears to the underwater rumblings, industrial gnashings, and overhead zoomings that make up the sonic environment surrounding the Newtown Creek, a body of water that separates Brooklyn and Queens and is one of the most polluted Superfund sites in the country. The creek is infamously known for the Greenpoint Oil Spill, where somewhere around 17 to 30 million gallons of oil and petroleum products seeped into the creekbed over the span of decades, only to be discovered by a Coast Guard patrol helicopter in 1978. Since being designated a federal Superfund site in 2010, many environmental remediation projects in the area aim to clean the water and surrounding ecosystem. Still, the area remains environmentally compromised due to industrialization, continued oil pollution from nearby refineries, combined sewage overflow events that regularly dump human waste into the creek, and toxic runoff from cars and trucks that drive across the busy streets, bridges, and highways that pass over and through the area.
An ariel photogrpah of Newtown Creek cutting between Brooklyn and QueensAnother view of Newtown Creek with Manhattan in the background
Despite this, the area piques my curiosity as both a harbinger of the climate crisis at our doorsteps and also as a potential stage for how we might learn to coexist with such a present-future. Sonically I’m drawn to the whooshing of cars that pass above on the Long Island Expressway, the stochastic bubbling of aeration systems meant to re-oxygenate the murky waters, and the resilient wildlife that still makes this once vibrant marshland home. If you’re lucky you may catch a glimpse of a stray egret searching for food among patches of sawgrass planted by ecological restoration projects. Crabs, jellyfish, and the occasional seal still swim below the creek’s still surface. Closer to the nearby Fedex distribution facility, cacophonous calls of birds suggest an area that isn’t so devoid of wildlife after all.
A photograph of the Fedex distribution facility
That is, until you realize that these bird calls are not made by living creatures. Rather, they’re a mix of artificial, pre-recorded birds that are meant to keep actual birds away from the inside of the distribution facility so they won’t nest or cause any unnecessary disruption to the continual churn of capitalism and industry. Having heard these calls, I was left wondering: What birds are these calls meant to be? (World-renowned birder Laura Erickson believes they might be American Robin or European Blackbird and some kestrels.) More interestingly, what birds were these calls meant to keep away? Are those “pest” birds even around anymore? If not, are these artificial bird calls singing out to phantom birds that no longer exist?
Curious about the poetic implications of these "Birds of FedEx,” and in keeping with my desire to learn more about audio machine learning during my time at the Recurse Center, I set out to make a bird sound classifier that could be used to identify birds in the Newtown Creek based on their calls. I had built an environmental sound classifier before, so the project was meant to get me more experience with audio scene classification. I was also interested in how identifying bird species could be useful for environmental remediation projects that require identifying and maintaining counts of animal species across a wide area—something that microphone arrays and sensors networks make possible. Finally, for my own creative and artistic investigations, I thought the idea of a bird sound classifier could help in my acoustic explorations of the Newtown Creek.
An photograph of a man holding a cellphone near the shoreline of Newtown Creek
I started by finding a suitable bird sound dataset to train on. The largest and most comprehensive one I could find was the BirdCLEF dataset, which comprises over 36,000 recordings of bird calls across 1,500 species native to Central and South America. Based on the work done in the BirdCLEF baseline system, I was able to organize the recordings into folders named after each of the bird species to be later used for classification training.
A screenshot of a computer terminal printing out the names of various species of birds
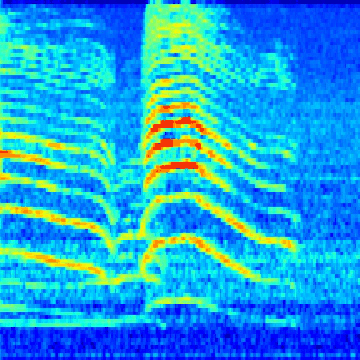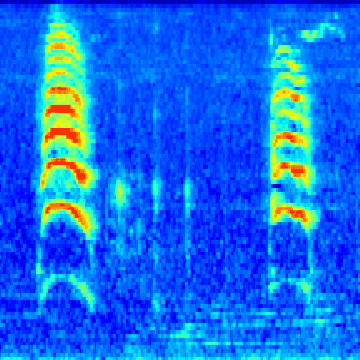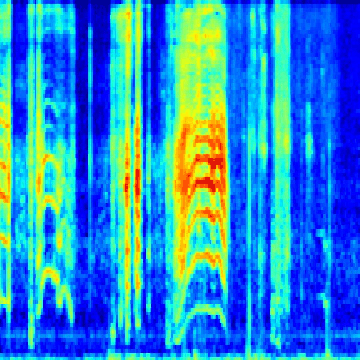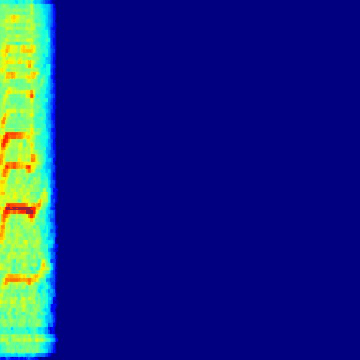
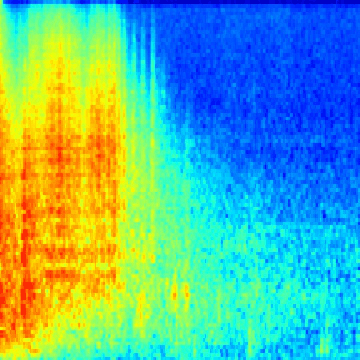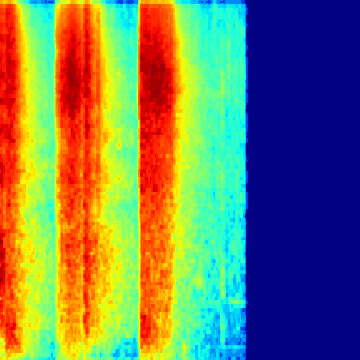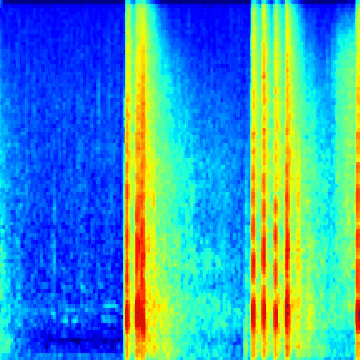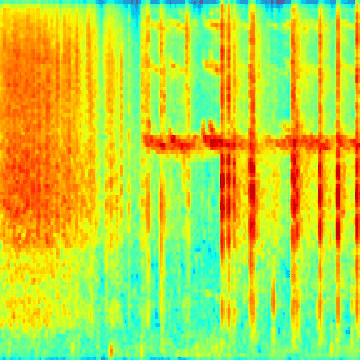
The next big hurdle was finding the bird calls in the recordings. Each recording lasts a few seconds to a few minutes, with no documentation of where in the recording the bird calls are (this is known as a weak-label problem, common in audio event classification where the onset and offset times of the event in question are unknown). I wrote code to scan through each of the recordings and cut them into one-second segments. From there, I applied a short-time Fourier transform on each segment to generate a spectrogram. Then, by using a heuristic, I was able to determine whether or not a segment contains a “chrip” (which I assumed to be a viable bird call). From there, I saved each spectrogram in a folder named after the corresponding bird species. The result was thousands of bird call spectrograms, nested inside their respective bird species folder, which I used for training a neural network. This animated GIF shows spectrograms generated for the Golden-Capped Parakeet (Aratinga auricapillus).
An animated spectrogram of birdsong audio
After preprocessing all of this audio data, the only thing left to do was to train a neural network to classify the bird calls. I opted to use fast.ai, a wonderful library that serves as a easy-to-use API on top of PyTorch, and does a lot of the boilerplate work for you in setting up and training a neural network. Since I was going to be training on spectrograms (images that represent the frequency content of a signal), I used a convolutional neural network pretrained on ImageNet. I used a technique known as transfer learning, which reuses most of a pre-trained network that’s already able to recognize visual patterns like curves and edges. The spectrogram training data was only used to “fine-tune” the last layer of the network. After many hours of training, the neural network was able to recognize bird calls from my validation set to an acceptable accuracy, validating this project and idea.
A screenshot of a Jupyter notebook showing a machine learning model in trainingAnother screenshot of a Jupyter notebook, this time showing the model classifying audio files into bird species.
Whisp is an environmental sound classifer that can be used to identify sounds around you. In its current form, Whisp will classify 5 second sounds with an 87.25% accuracy across a range of 50 categories, based on the ESC-50 dataset. You can also record sounds in the field to get a another perspective of what is happening in your sonic environment.
You can try the app here! It works on desktop Firefox and mobile only Safari on iOS (Chrome has some issues that don't let using the microphone for recording work right now, sorry!).
Trying the "Record your sound" feature on your computer might not get very satisfying results because, well, most of us are on a computer in pretty sonically uninteresting places. Definitely give it a shot on your mobile device when you're out and about, surrounded by more interesting environmental sounds :)
Introduction
As someone who has spent a lot of time recording and listening to sounds, the idea of a generalized sound classifier has always been a dream of mine to build.
I'm interested in creating technologies that change our relationship to the sounds in our environment. Or another way, I like creating sound technologies that change our relationship to our environment and the world at large.
I'm finding my interests moving more towards research in audio event recognition, so Whips is a first attempt to dive into that world.
Some applications that I've wanted to use one for include:
A tag suggester for field recordings
An augmented reality app that identifies sounds around you for the hard-of-hearing community
A tool for sound artists for analyzing audio events in your surroundings
To those ends, I built a environmental sound classifier using the ESC-50 dataset and fastai library.
In this write up I will walk through the steps to create the classifier, as well as drop hints and insights along the way that I picked up from the fastai course on deep learning.
This dataset provides a labeled collection of 2000 environmental audio recordings. Each recording is 5 seconds long, and is organized into 50 categories, with 40 examples per category.
Before training the model, its useful to spend some time getting familiar with the data in order to see what we are working with.
In particular, we are going to train our model not with the audio files, but with images generated from the audio files. Specifically, we will be geneating spectrograms from the audio files and train them with a deep learning neural net that has been pre-trained on images.
For more information on how I generated the spectrograms from the audio files, check out my spectrogram generator notebook on how I did this.
One thing to note is that with spectrogram images, I was able to get better accuracy by creating square images rather than rectangles, so that the training would take into account the entire spectrogram rather than just parts.
Training
To train the model, we are going to use a resnet34, use our learning rate finder, and train twice over 10 epochs.
From the fastai forms, I was able to get a general sense of when I'm overfitting or underfitting.
Training loss > valid loss = underfitting
Training loss < valid loss = overfitting
Training loss ~ valid loss = just about right
epoch
train_loss
valid_loss
error_rate
1
1.063904
1.055990
0.325000
2
1.036396
2.332567
0.562500
3
1.049258
1.470638
0.387500
4
1.032500
1.107848
0.337500
5
0.924266
1.392631
0.417500
6
0.768478
0.623403
0.212500
7
0.596911
0.535597
0.165000
8
0.446205
0.462682
0.160000
9
0.325181
0.419656
0.135000
10
0.251277
0.402070
0.127500
Nice! That gets us an error rate of 0.127500, or 87.25%!.
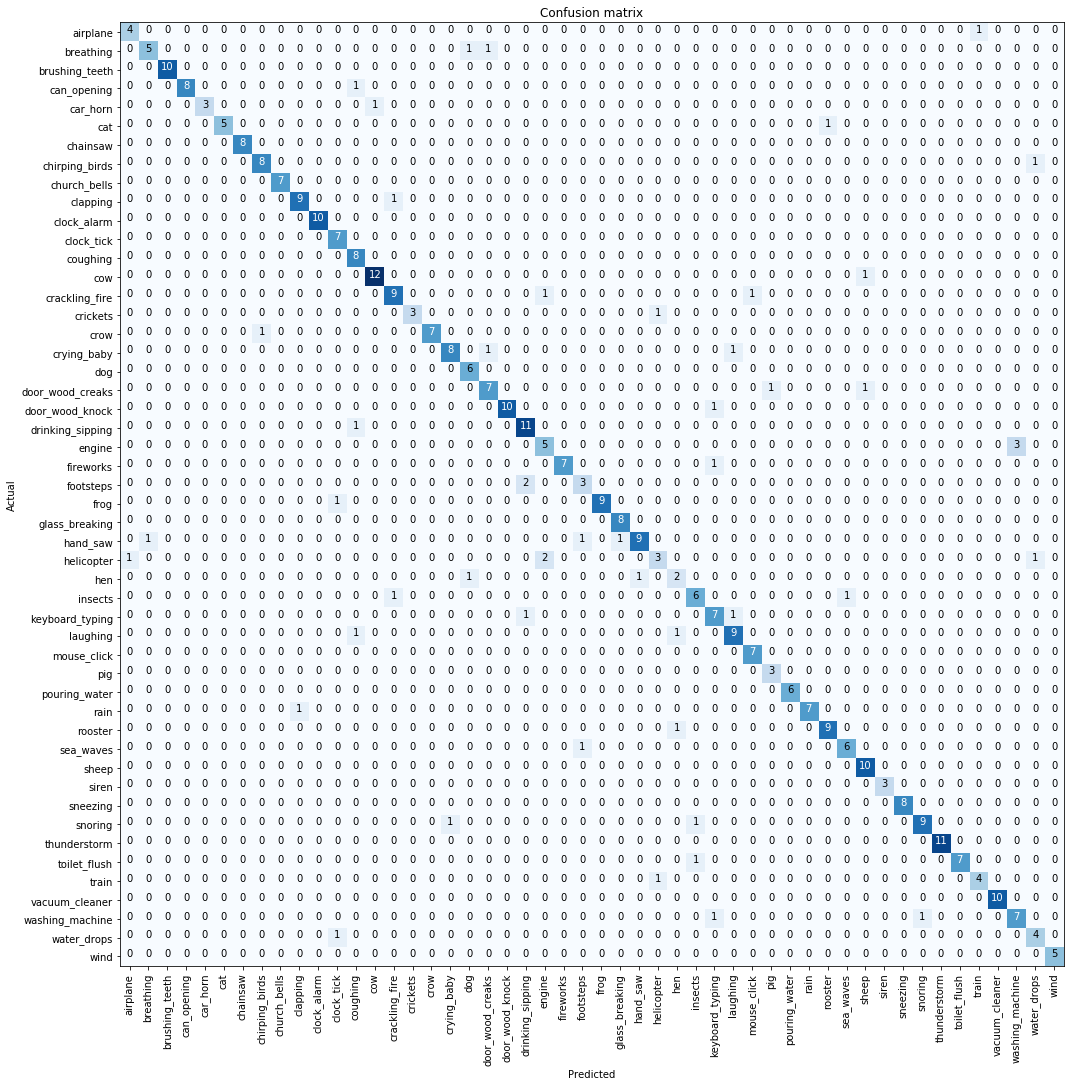
Here is our confusion matrix which looks pretty good.
Whisp Confusion Matrix
Testing in the Field
I've been taking Whisp with me out on field recording expeditions around the Newtown Creek.
Dutch Kills
One night with Mitch Waxman, I took an early version of Whisp and made field recordings around the Dutch Kills area of the Newtown Creek, and down near Blissville. I extracted 3 sounds from the recordings that I knew would show up in the ESC-50 dataset categories.
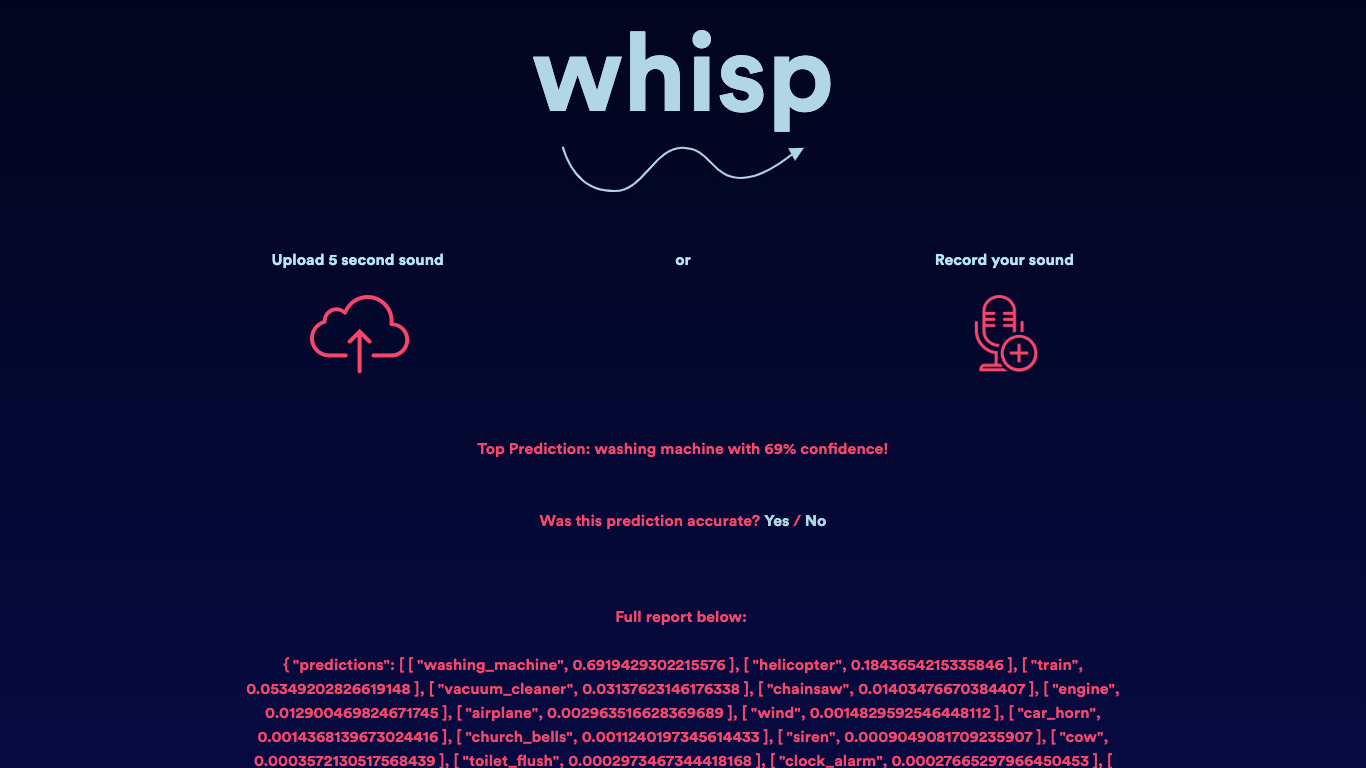
Train Engine
Whisp classified this sound as a washing machine with 69% confidence, which... isn't exactly correct. But hey, a washing machine does sound a lot like an engine when its running right? I can understand the ambiguity. Whisp had 18% confidence that it was a helicopter, and 5% confidence that it was an engine (of some sorts).
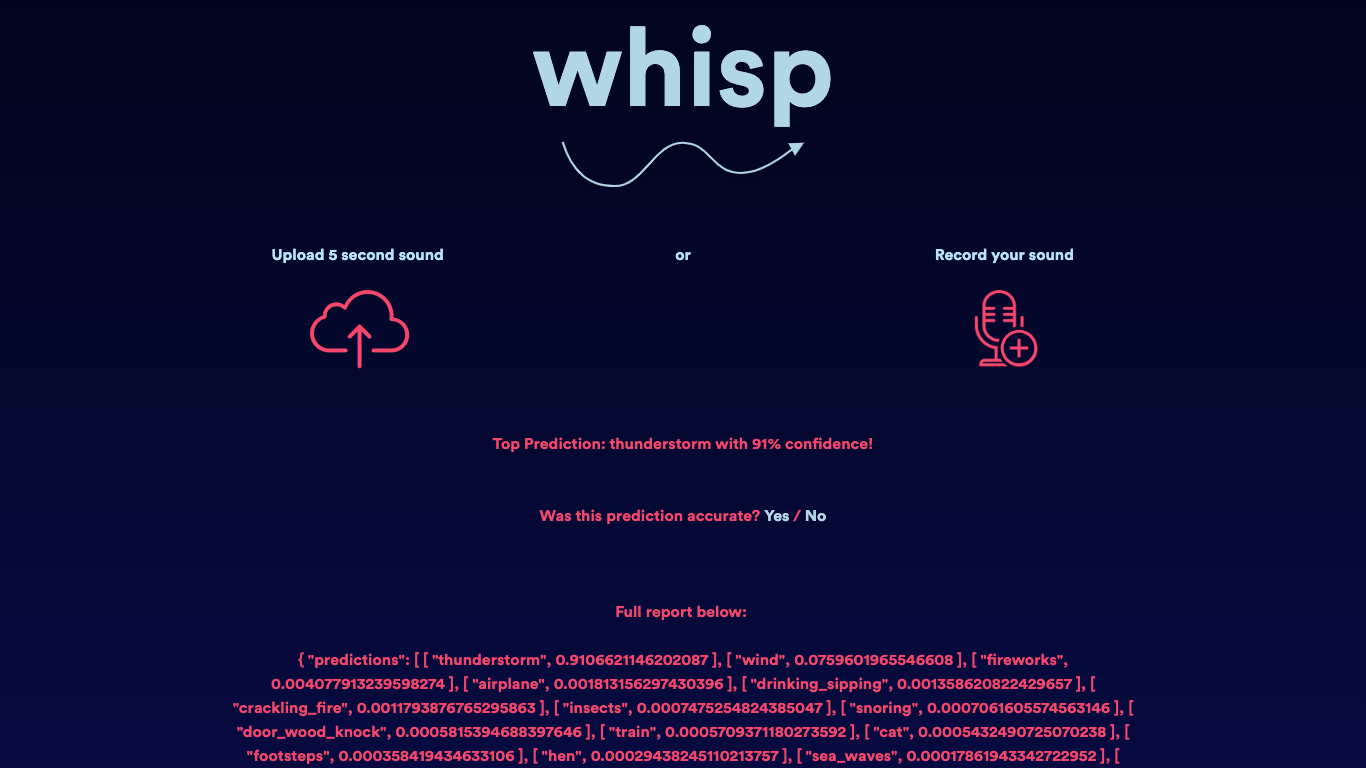
Wind
Whisp classified this sound as a thunderstorm with 97% confidence, which are usually pretty windy! The next highest confidence score was wind, with 7% accuracy.
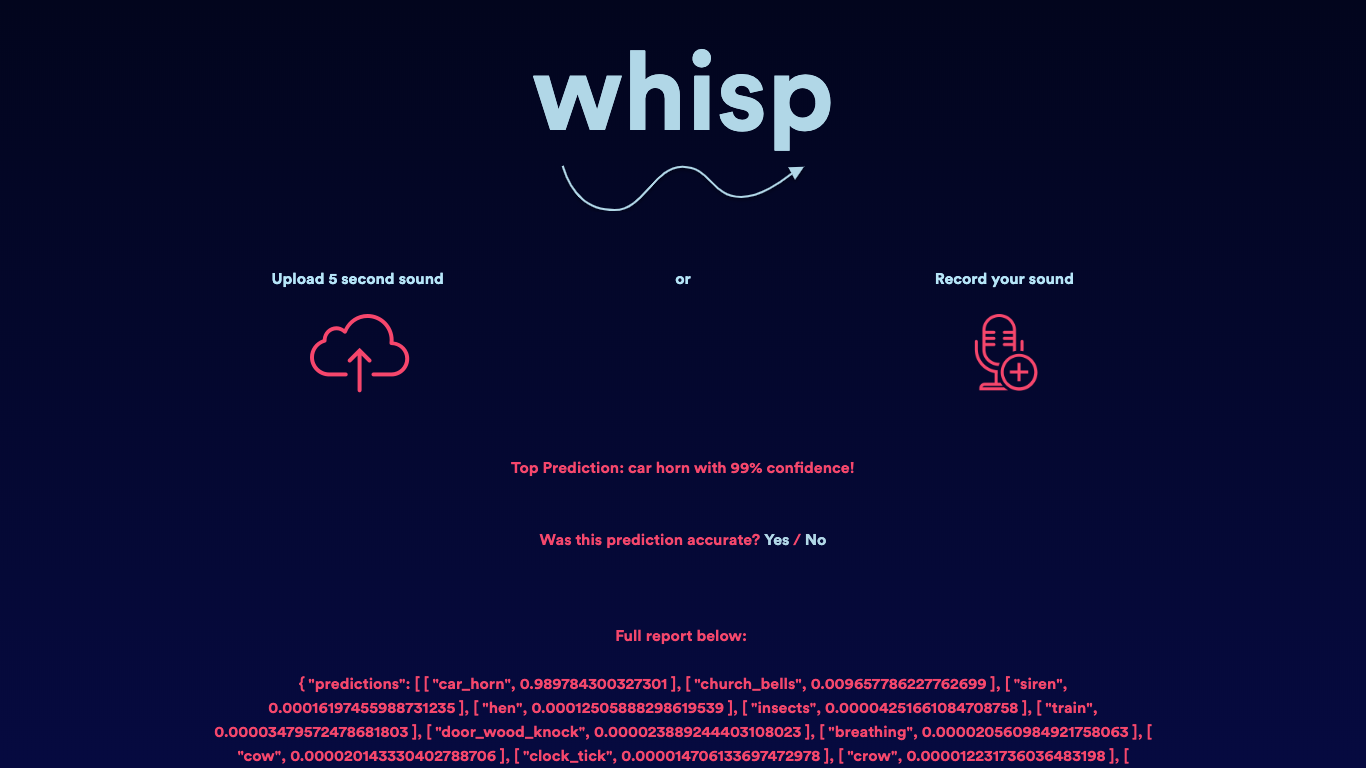
Train horn
Finally, Whisp classified this sound as a car horn with about 99% accuracy. Given that the dataset doesn't have "train horn" as a category, we can live with this being close enough ;)
Hunter's Point Park (Hunter's Point South Park Extension) - mouth of Newtown Creek
I recently took Whisp out into the field with Taiwanese sound artist Ping Sheng Wu to test Whisp in the field.
We saw a group of birds off into the distance.
Whisp was able to hear and classify their chirping!
We tried getting some water sounds, but most of it came back as wind, as that was the dominant sound out there. Sea waves did come back though, but with a low 3% confidence rating.
On our walk back to the train station, we found a fan and decided to try Whisp'ing it.
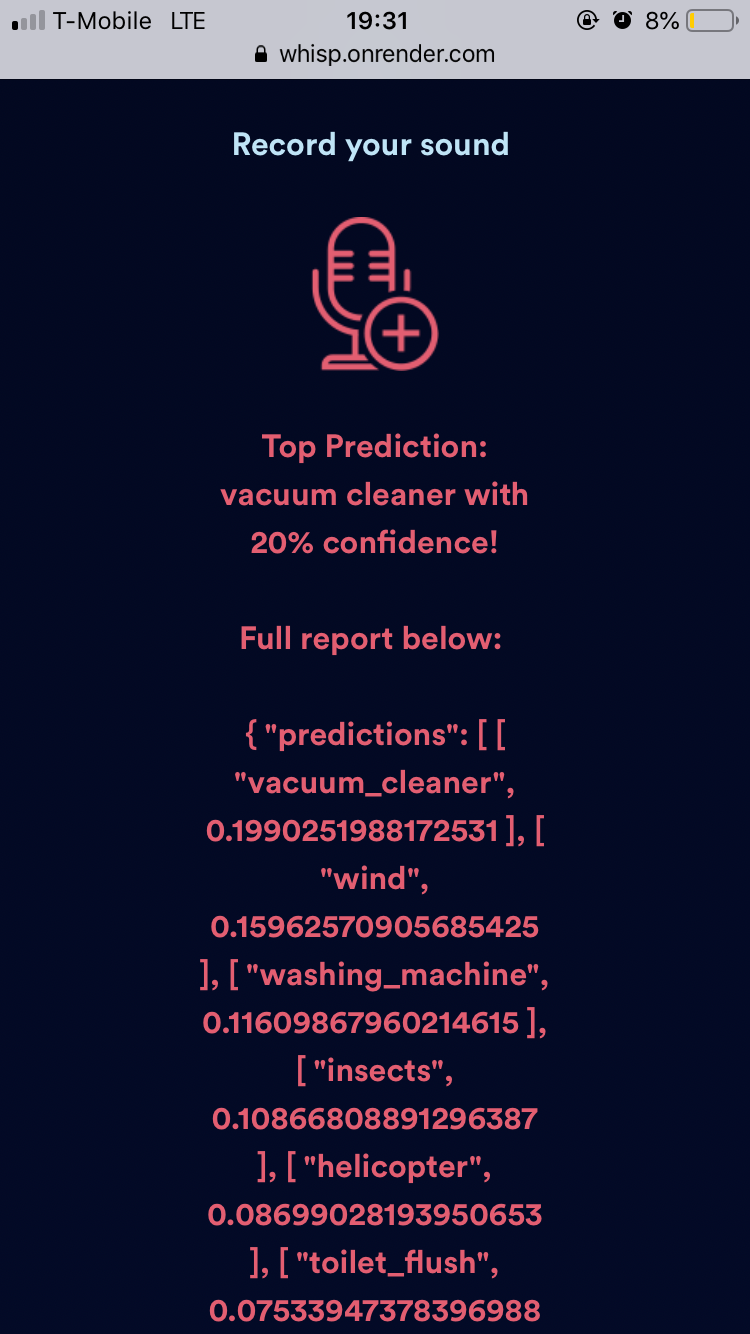
Whisp thought it was a vaccum cleaner, which, like the example above of the engine that sounded like a washing machine, isn't too far off. It also thought it could have been a washing machine and plain old wind.
Testing in the wild
Since releasing Whisp I've taken it out with me to try to classify sounds around me, which it does a really good job at!
Here are some examples of it classyfing sounds like:
Birds
Sea Waves
Ambulance Siren
Fireworks
Clapping
Future Paths Forward
I'd like to train this model on Google's AudioSet data.
I'm also interested in Exploring more data augmentation methods as described in Salamon and Bello's paper on Environmental Sound Classification.
Some ideas that I'd love to explore are the idea of a "sound homonym". For example, there are a lot of sounds that sound similar to each other, and that the classifier gets wrong but is pretty close (washing machine vs. engine, for example). I wonder what it would look like to play around with sound homonyms for performance.
The other thing that I'm interested in is the "distance" between sounds. For example, the classifier gives you the "closest" prediction it thinks the sound is. You could imagine that the prediction that is the least close is the furthest away. It would be interesting to push this idea further and think about how different sounds are more or less distant from each other. What would it mean for a sound to be the opposite of another sound? Or the most different sound?
Labocine is a new platform for films from the science new wave. In the iOS app, you can browse Labocine's monthly ISSUES for a special selection of exclusive science films every month and read about the scientists and filmmakers leading the science new wave in SPOTLIGHTS.
Format No. 1 is a novel optical sound experience that consists of an iPhone application and visual scores. For this project I developed an iOS application turns the iPhone into an optical sound device and visual scores / installations.
Format No. 2 is a novel optical sound experience that consists of an iPhone application and visual scores. For this project I developed an iOS application. The iPhone application uses computer vision algorithms, to recognize circles and plays a soundscape depending on the size and the location of the circles it sees.
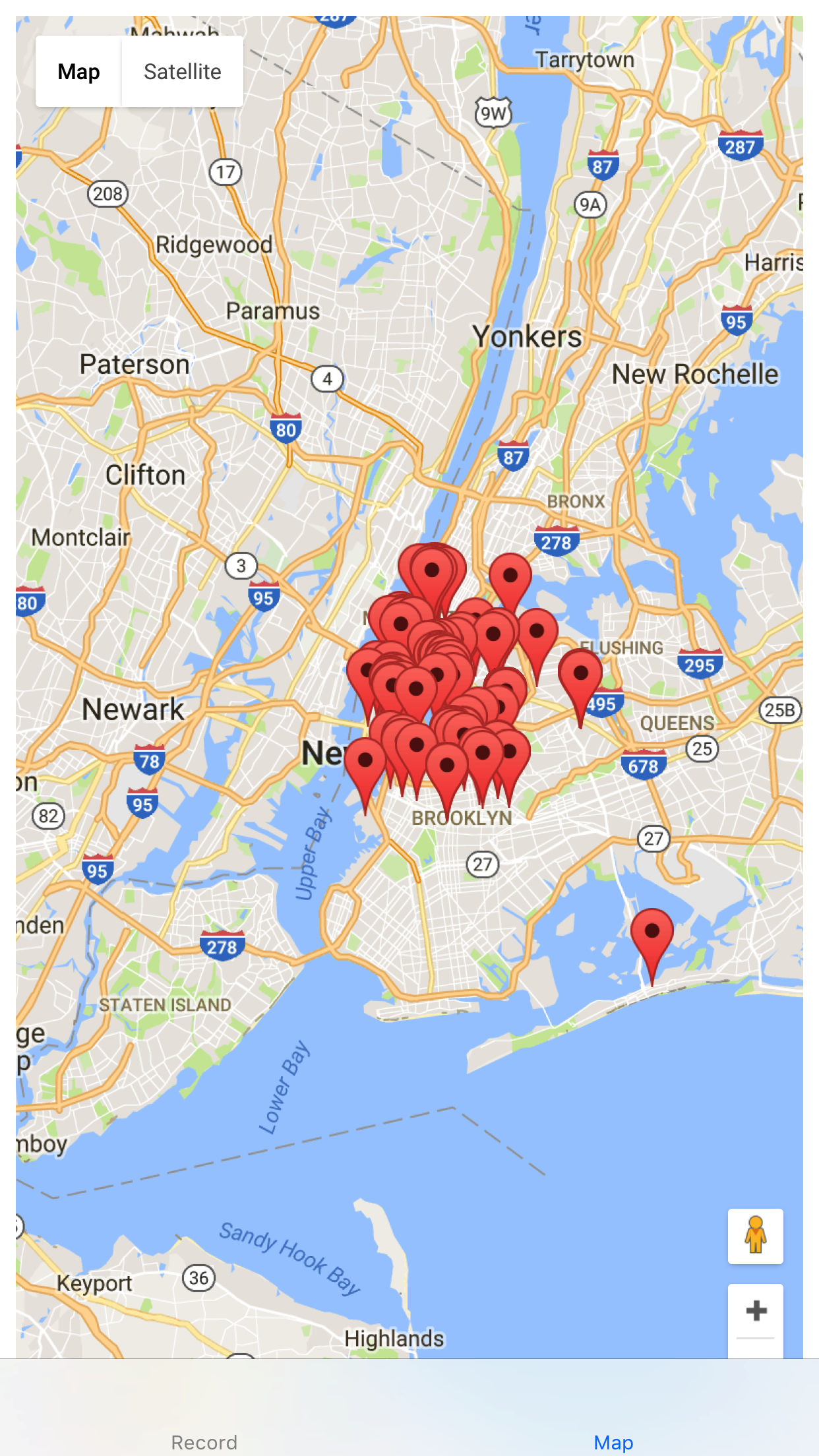
Transient allows you to record sounds and quickly upload them to a map so you can listen to the world around you!
Simply hold down the record button and let go. When you're done, go to the map view and see your sound where you recorded it! You can also listen to sounds other people have recorded.