
Week 4: Chirps
Published on 01.31.2020 in [rc]
This week at RC I focused on preparing by bird sound dataset for traning next week. I decided to go with the LifeCLEF 2017 dataset, which "contains 36,496 recordings covering 1500 species of central and south America (the largest bioacoustic dataset in the literature)". Much of my week was spend reimplementing a spectrogram generation pipeline from the BirdCLEF baseline system, which used this same dataset.
The pipeline goes through all the 1500 classes of bird species, and for each recording, the piplelne creates one second spectrograms across the entire recording (with a 0.25 second overlap between each generated spectrogram). From these spectrograms, a signal-to-noise ratio is produced to determine whether or not the spectrogram contains a meaningful signal that we use to determine if it contains a bird vocalization of that species.
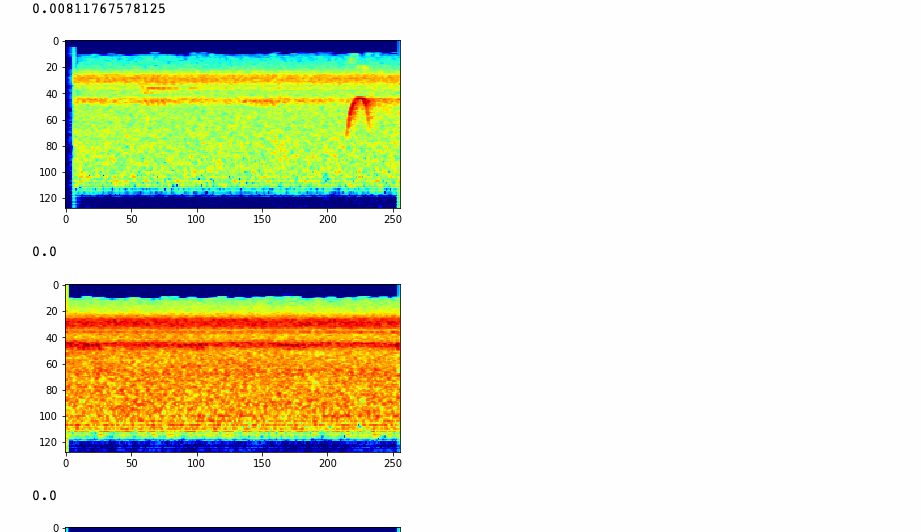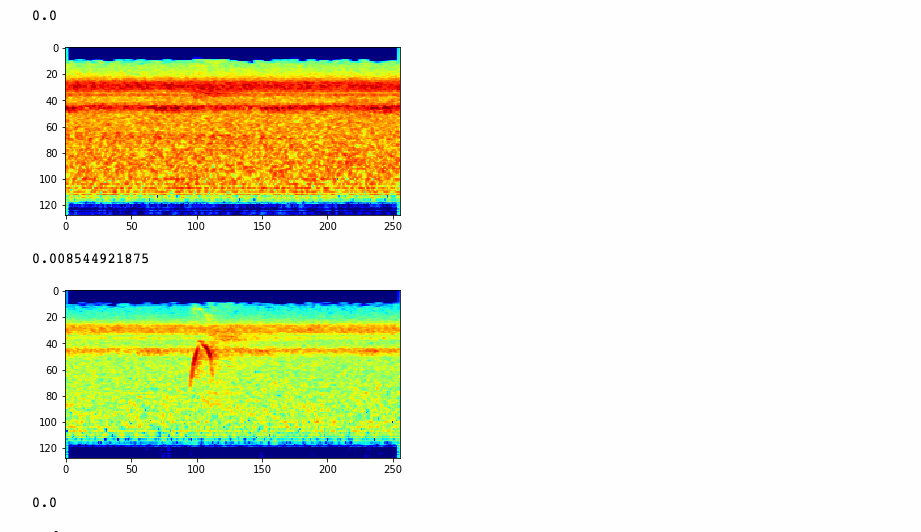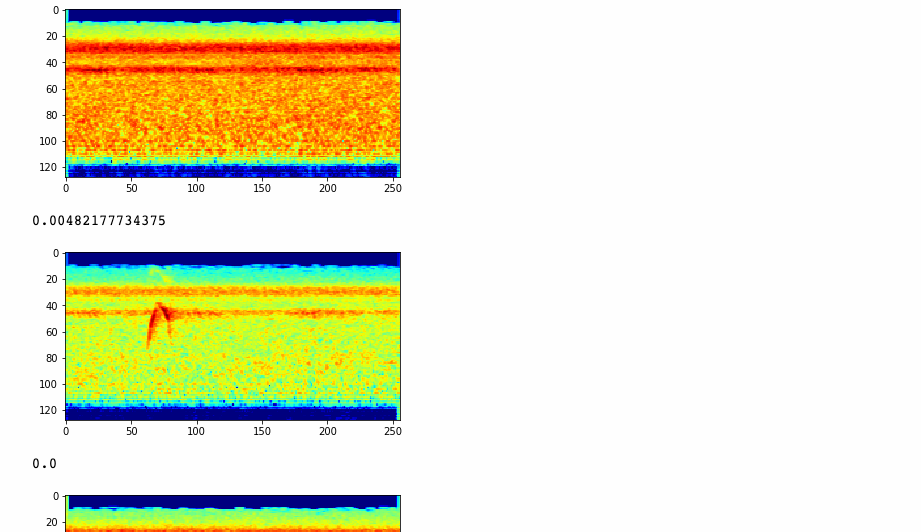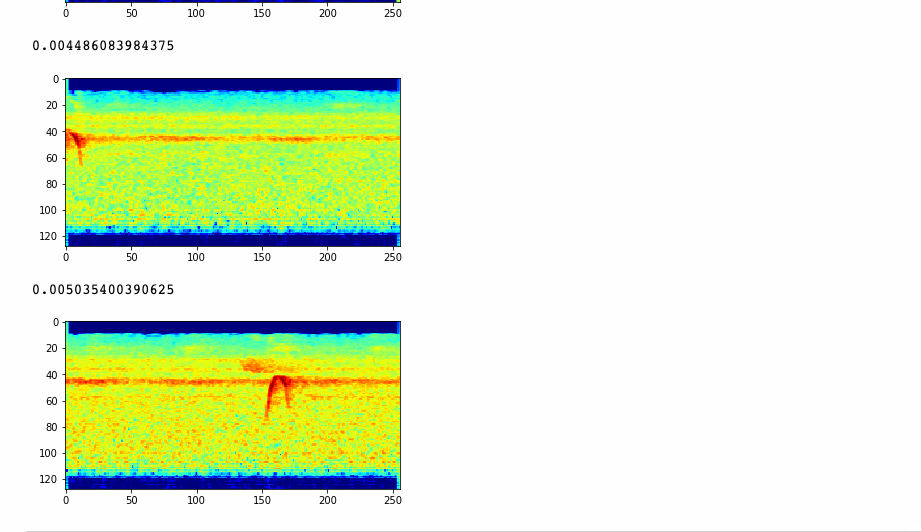
If the signal-to-noise ratio is above a certain threshold, we save that spectrogram in a folder for that bird species. If not, we save that noise-y spectrogram to be usedlater for generalizing during training.
This whole process takes an estimated six hours to run, and it results in about 50,000+ spectrograms across the 1500 classes of bird species.
My intuitive feeling about this process is that it is a bit heavy-handed, suseptible to inaccuracy, and not very efficient. However, I can understand the approach and ultimately it does get the job done. I do think this paper on Eventness (a concept for audio event detection that used the idea of "objectness" from computer vision and applies that to detecting audio events in spectrograms) proposes a more nuanced way to pull out meaningful sonic "events" in a recording. It might be something worth incorporating in another pass on this system.
I'm happy I achieved my goal for the week of generating the spectrograms from the recordings! I have been full of doubts though of how this fits into my larger goals. I think this week I fofocused on the "trees" and not the "forest", so to speak, and maybe what I'm feeling is getting a bit lost in the forest. With most of the data processing out of the way, I'm xcited to pull out a bit and think more about the context of what I'm working on and how it fits into my overall goals.
For instance, generating all of these spectrograms with this pipeline has moved me way from contributing to the fastai audio library. If I had wanted to keep down that path, I would have had to really work to not cut up the spectrograms in the way that I did, and instead come up with a way to generate the onset/offset times of the bird vocalizations from each recording and do the on-the-fly spectrogram generation with the built-in fasai audio library tools. I think that doing the actual learning task is what I want to be focusing on though, so maybe that makes it ok that I reimplemented another way of doing it, because it serves my end goal of diving deeper into the learning part of classification (it is something I would love to go back and dig deeper into though).
With that observation in mind, I think that focusing on training a neural network on these bird vocalization spectrograms next week will get me back into contributing to the library and focusing on the things I want to learn. I don't think this particular bird classification project will lead me to fixing the batch display issue, for example. I think that's okay, and maybe it will just be something I circle back to later on when trying to do other classification tasks with the other datasets I'm interested in.
I think going back to my larger goals at RC, I want to create a real-time sound classification application that can be used to classify different kinds of sounds. I've made a model for environmental sounds, and now I'm tackling bird vocalizations. I want to look at other environmental sound datasets, and if I have the time, I want to do speech as well. I think having this app as a "wrapper" application that lets you do, in general, real-time classification with any model you import will give me the room to d training on many different datasets, giving me more opportunities to dig into fastai v2, the audio library, convolutional neural networks, real-time on-device machine learning, short-time Fourier transforms, and classification in general.
So for now, my goals are to finish up the bird classification system, get it on device, and then make more models to get better at using deep learning for sound classification and understanding what it takse to do real-time on device machine learning.