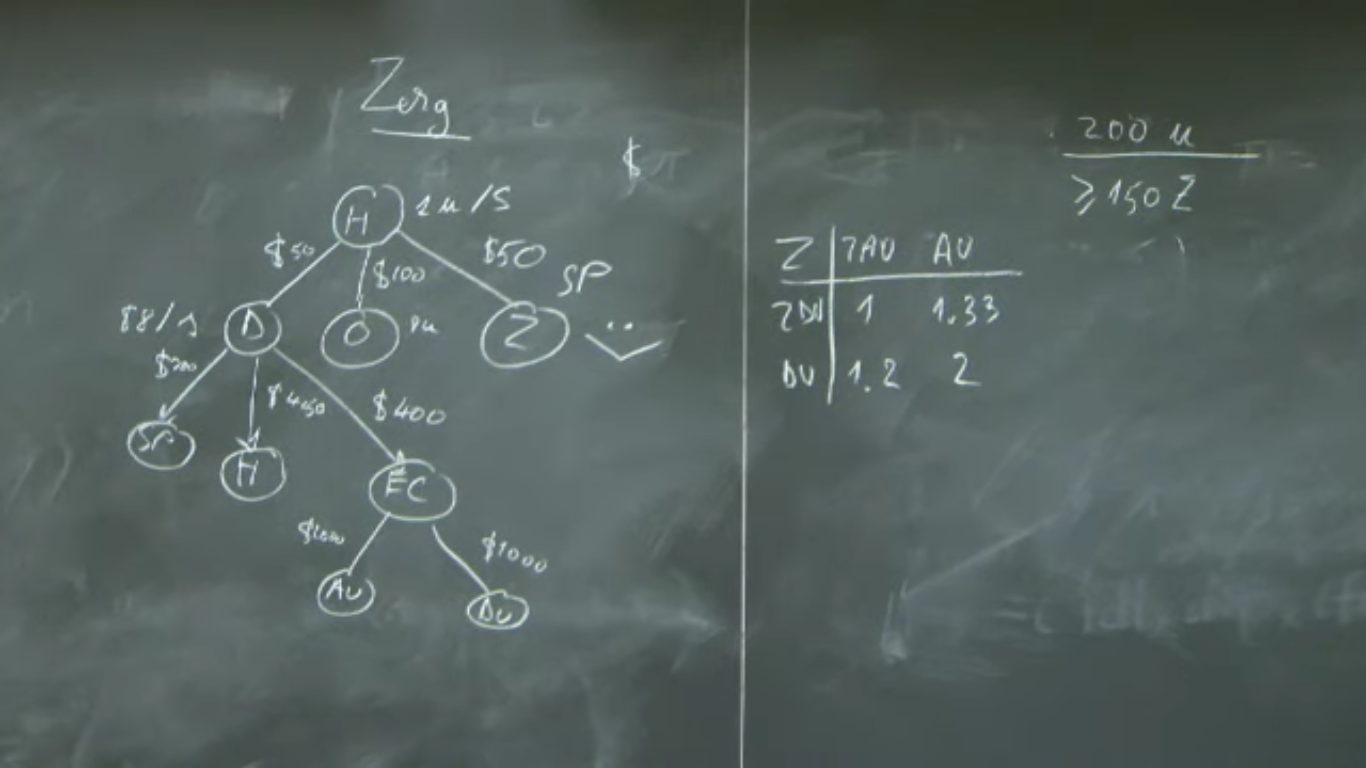This was my last week in batch at the Recurse Center, and what an experience this has been :). I'm so thankful for the community and what we were able to do these past two weeks in making remote RC work so well. I'm grateful for everyone at RC, including the faculity, everyone in batch, and the supportive alumni community. As we say here, we "never graduate", so this isn't the end of my time at RC, just the end of a long beginning on-boarding process into the RC community.
I spent most of my programming time this week working on my real-time audio classifier mobile app in Expo/React Native. I spent most of my time trying to understand the capabilities of Expo's expo-av library. Audio data isn't easily accessbile, so I had to figure out how to save an audio file, and load it back as binary data. I was able to get that far, and wanted to try drawing the audio signal to the screen. Unfortunately I had a lot of difficulty with this, due to the fact that most documentation I came across doesn't use stateless functional components, so I had trouble converting those examples to this more modern React Native paradigm.
Here are some drawing/2d canvas references I came across:
This was also my last week watching video lecture's for MIT's 6.006 couse, Introduction to Algorithms! It was such a solid class, I highly recommend it. I'm looking forward to studying more during my time at Pioneer Works, now with this foundational material under my belt :)
Alas, this is my last write up for my time at RC. Its been real! I'm looking forward to staying involved with the RC community. Never graduate!
This was our first week of Remote RC. I spent most of the week adjusting to this new normal, trying to create some positive habits while working from home (still getting up at 7am and going for a bike ride, stopping work around 7pm). There were some highs and lows this week - I think everything is day-to-day right now. All said, I did accomplish a few good things this week.
I made some progress on Whisp v2, and I'm at a point now where I can finally get audio data out of Expo's AV library (albeit kind of crudely). Hopefully by the end of next week I can show of something intesting like doing a STFT with that data. Follow along on the Whisp app repo.
Here are some links on some on-going research on getting audio data in Expo/React Native:
Otherwise this week I started up fastai's 4th version of Deep Learning for Coders, while working on finishing up part 2 of their previous version. I'm kind of behind but trying to keep up!
This week I also watched more of MIT's 6.006 - mostly on Dynamic Programming this week. A lot of it I think will only make sense with practice, so I'm excited to start doing more dynamic programming problems and go back to these videos as reference in the future.
Next week is my last week at RC :( I'm hoping to just keep coding and working on my projects up until the last day. Maybe I'll try streaming in Twitch? Heh. We'll see. By next week I hope to 1) Finish 6.006 lecture! 2) Be caught up on Fastai lessons 3) Have STFT working in JS
Whew. Quite a week. With all the news and everything going on with the global pandemic, its been a bit of an unproductive, chaotic week. I do want to just write at least something about what I did, just to keep these posts going...
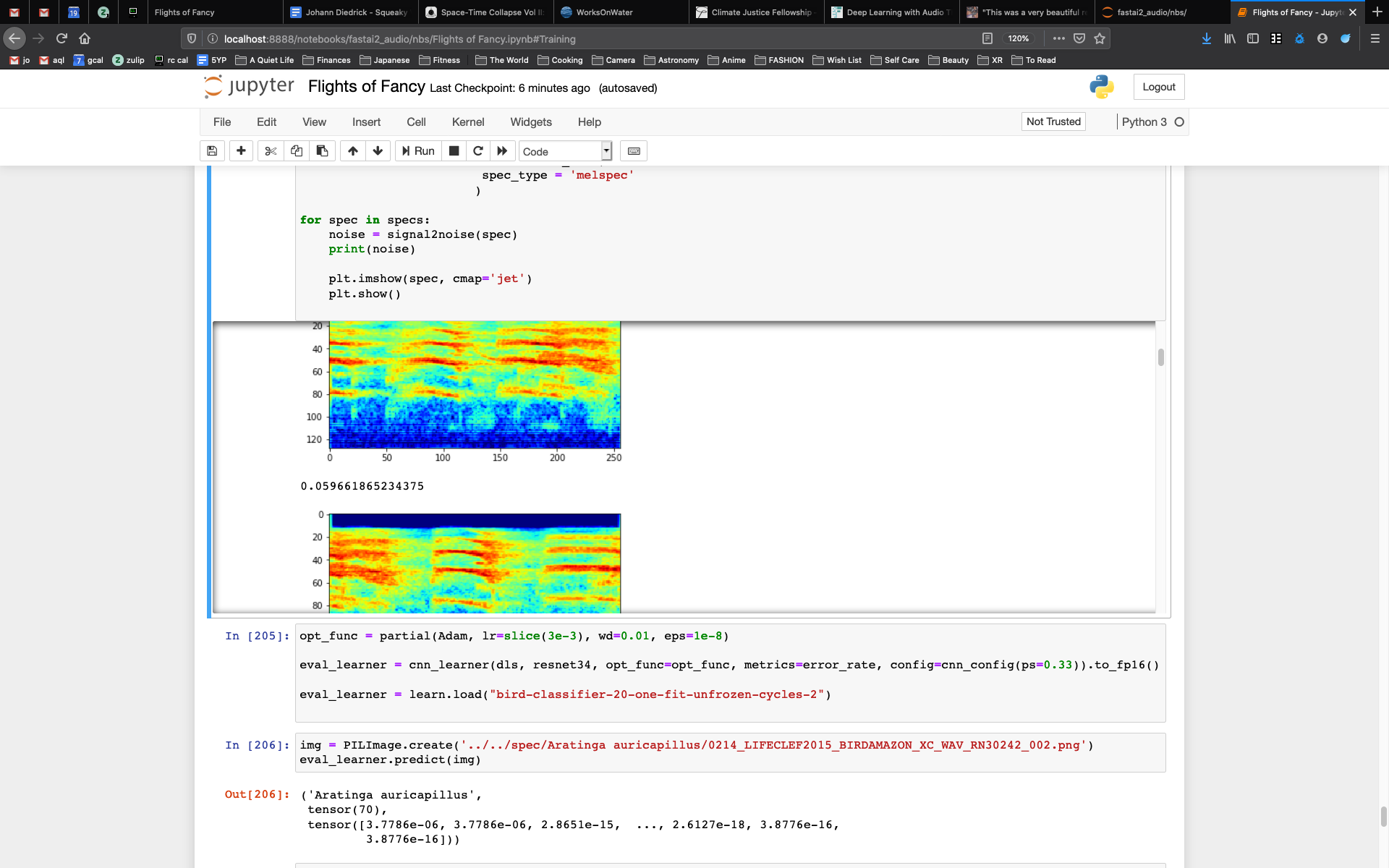
This week I have been extending my work on Flights of Fancy in collaboration with Kelly Heaton to take a recording of her electronic bird sculpture and run it through my bird sound classifier to see what bird specieies it predicts.
We started by taking a recording of Kelly's electronic bird sculptures:
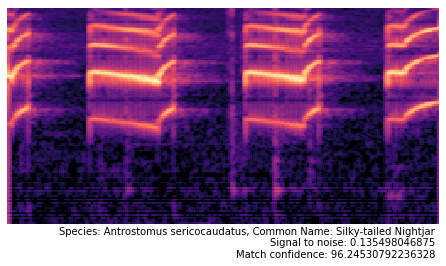
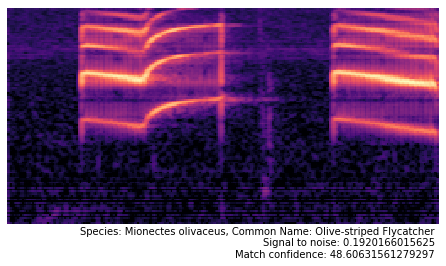
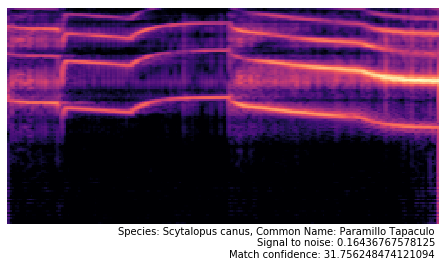
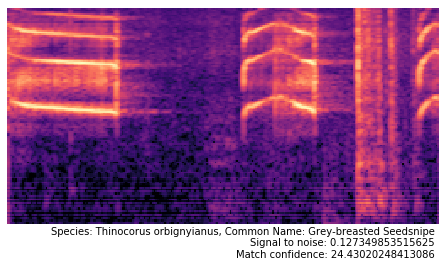
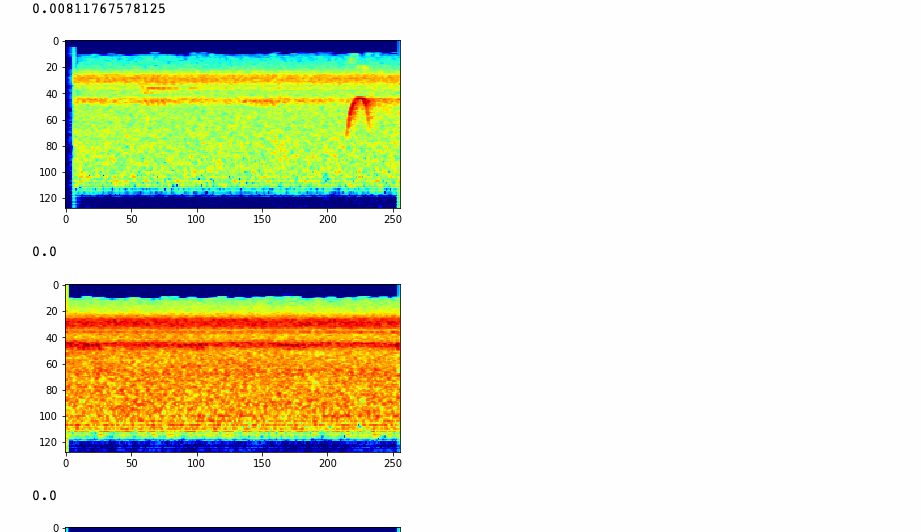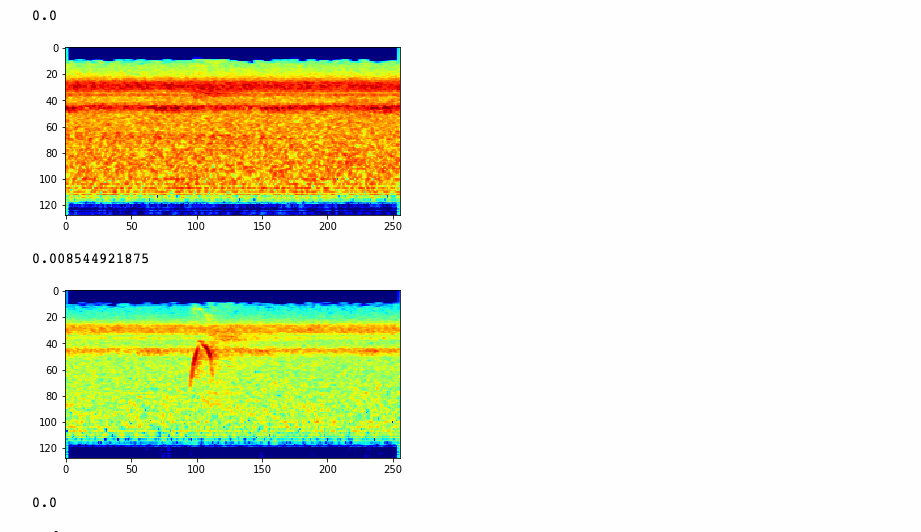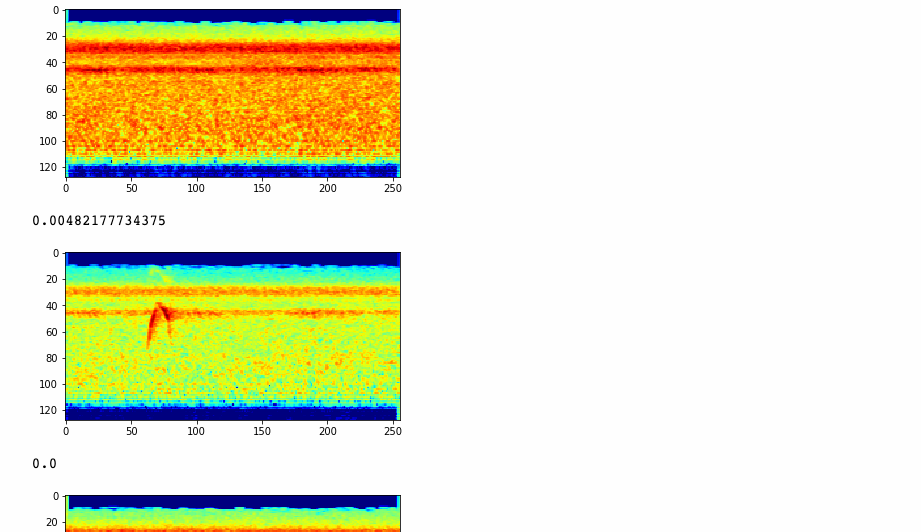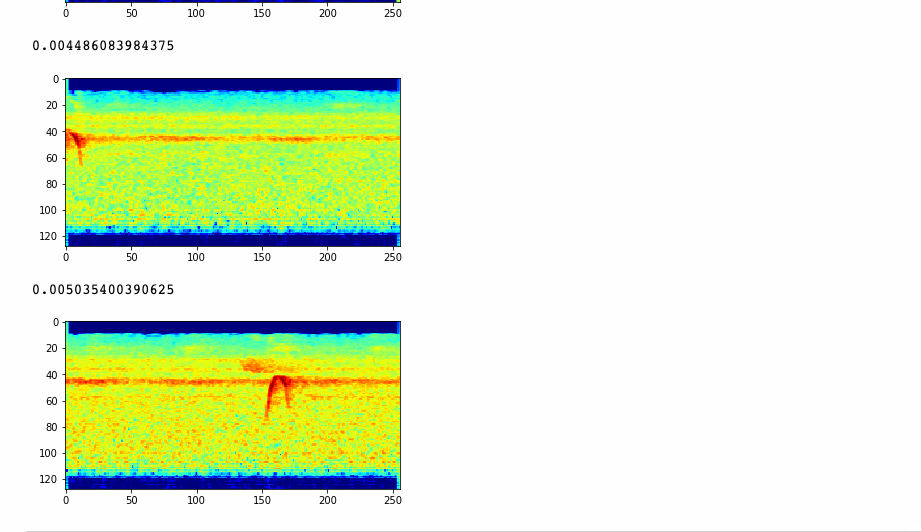
Then I used my Flights of Fancy software to extract spetrograms from that recording, and ran them against my classifier to see what birds it predicts these sounds came from. Here are some results:
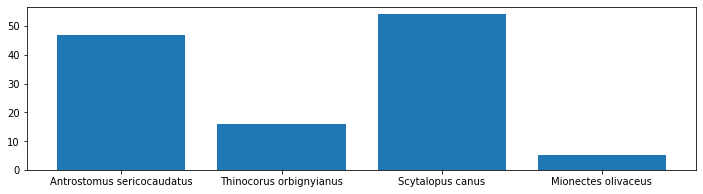
We also produced a bar chart showing the amount of of times a speicies was detected over the 122 segments.
For the Machine Learning Study Group, we are all collectively reading a paper on Independent Component Analysis, and I'm individually going to read about Autopool.
With that, for next week I plan on continuing on with 6.006, fastai lessons, implmenting STFT in JS/React Native for the Computational Audio Study Group, and doing some more audio ML/reading of papers for the Machine Learning Study Group.
Back at RC, I started working back on my real-time audio classifier mobile app. One of the things I need to work on is generating spectrograms in my app. I opted to use React Native in order to have it work cross-platform, so for now I'm working on implementing some essential DSP algorithms in Javascript (which is not really a programming language I use often or feel very proficient in). I'm hoping just by doing this project I'll get a lot better at DSP, Javascript, Reactive Native, and eventually doing real-time audio ML on embedded/mobile devices. Quite a tall order / high mountain to climb, but I know its going to feel great once I get there :)
For now I'm researching how to perform the FFT in Javascript. Here are some of my current research notes:
I didn't get very far with it this week, but having done some initial research I feel good about moving forward with it more next week (especially now with more free time now that ASPMA is done!)
On the audio ML front, I've gotten back in touch with the fastai audio library team and I'm looking forward to contributing to something starting next week. For now, I put my bird sound classifier up on Github, to share with others: Flights of Fancy
As always, I kept up with 6.006 again this week as well as the fastai pt 2 video lectures. Looking forward to continuing that work next week!
This week felt like more of a continuation of last week. Instead of much coding, I was coming down from my talk at the Experiential Music Hackathon, and spent most of my time/mental energy on my talk for Localhost and my performance at the Un/Sounding the Relational City conference - both of which went really well!
Animated GIF of spectrograms generated from the calls of the golden-capped parakeet
Batch of spectrograms generated from calls of the Golden-capped Parakeet, found in Brazil and Paraguay and currently threatened by habitat loss
This week felt like the first time in a long time where I could take a breath and try to sit back without heads-down working. I'm going this signals a move from me being aggressively inward facing to a space where I'm a bit more loose and relaxed while at RC, open to new things and finding time to work in a more loose, less structured way. We shall see...
This week I finished the Audio Signal Processing for Music Applications course on Cousera, which was pretty amazing. I feel like I got exposed to a lot of fundamental audio signal processing concepts, as well as had the opportunity to practice them programatically. Moving forward with my real-time audio classifier, I'll definitely need to implment short-time Fourier transformations and log-mel-spectrograms, so I feel like with this course, I now have the tools to not only implement these algorithms but to deeply understand them from a theoretical point of view, as well as how and why they are used.
Vocaloid
It also turns out that the MTG group worked on Vocaloid!
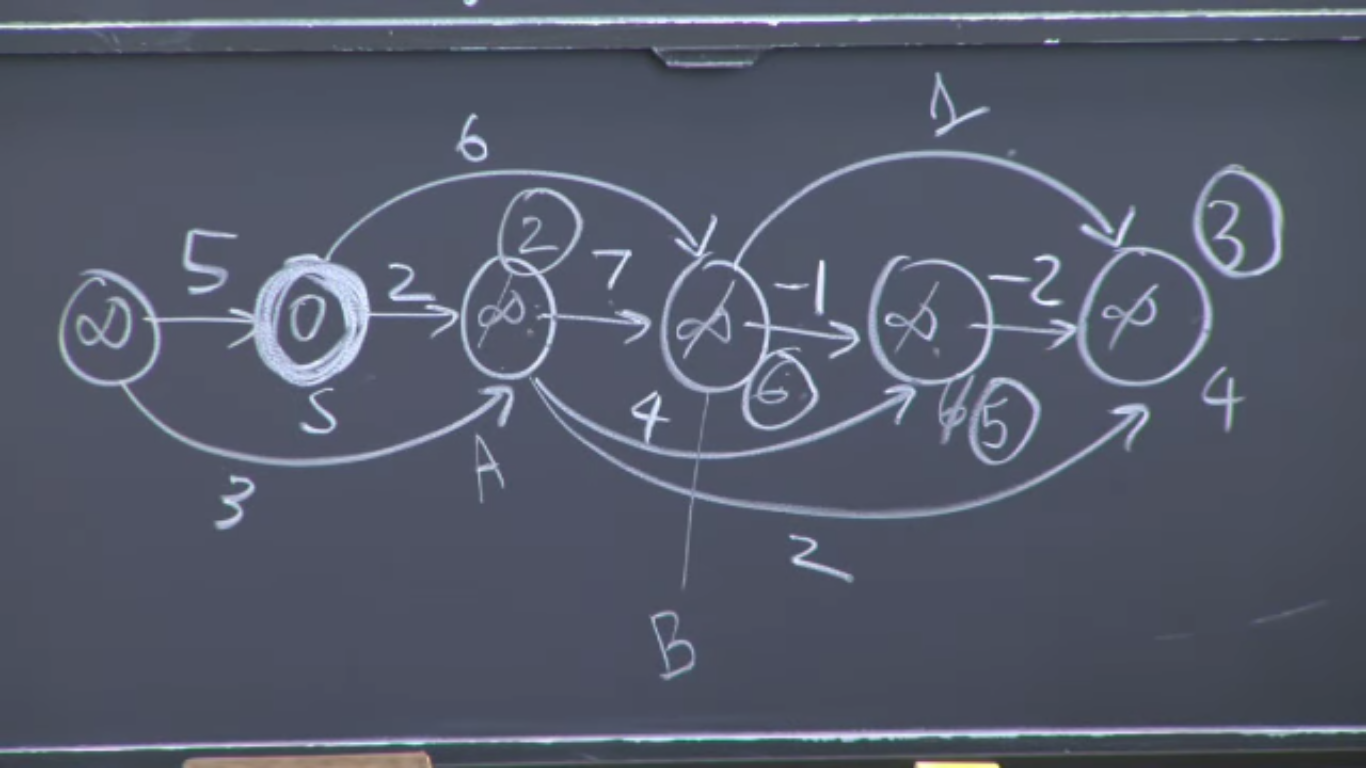
In 6.006 news, we learned about shortest path algorithms this week - from a more general point of view and with Dijkstra's algorithm.
Graphs
What I thought was a beautiful diagram about graphs
Starcraft
Using starcraft early game / rushing build order as an example shortest path problem
My plan for the following week is to bring my real-time audio classifier app back to the fore front and use all the programming I learned in ASPMA to help implement any of the audio signal processing I come across to finish the project.
At this event, I'm going to be talking about how attuning our hearing to environmental sounds can inspire new ways of music making.
The second talk is at Localhost, a series of monthly technical talks in NYC, open to the public, and given by members of the Recurse Center community. I will talk about using fastai’s new audio library to train a neural network to recognize bird sounds around the Newtown Creek, an ecologically compromised estuary between Brooklyn and Queens.
I was able to clean my notebook up to show off how training works, from getting the dataset to performing inference! It should end up being a pretty great presentation :)
Here is a video of us performing a version of it earlier last year at H0L0:
Because of all of that, I haven't done much coding this week. I did do a fair amount of coding to clean up my bird classifier notebook, which I'm now calling Flights of Fancy (which is also the name of my Localhost talk :D).
Otherwise, I kept up with my video lectures, watching week 9 of the fastai's deep learning course, week 9 of ASPMA, and Lecture 13 and 14 from MIT's 6.006 course.
Cycles
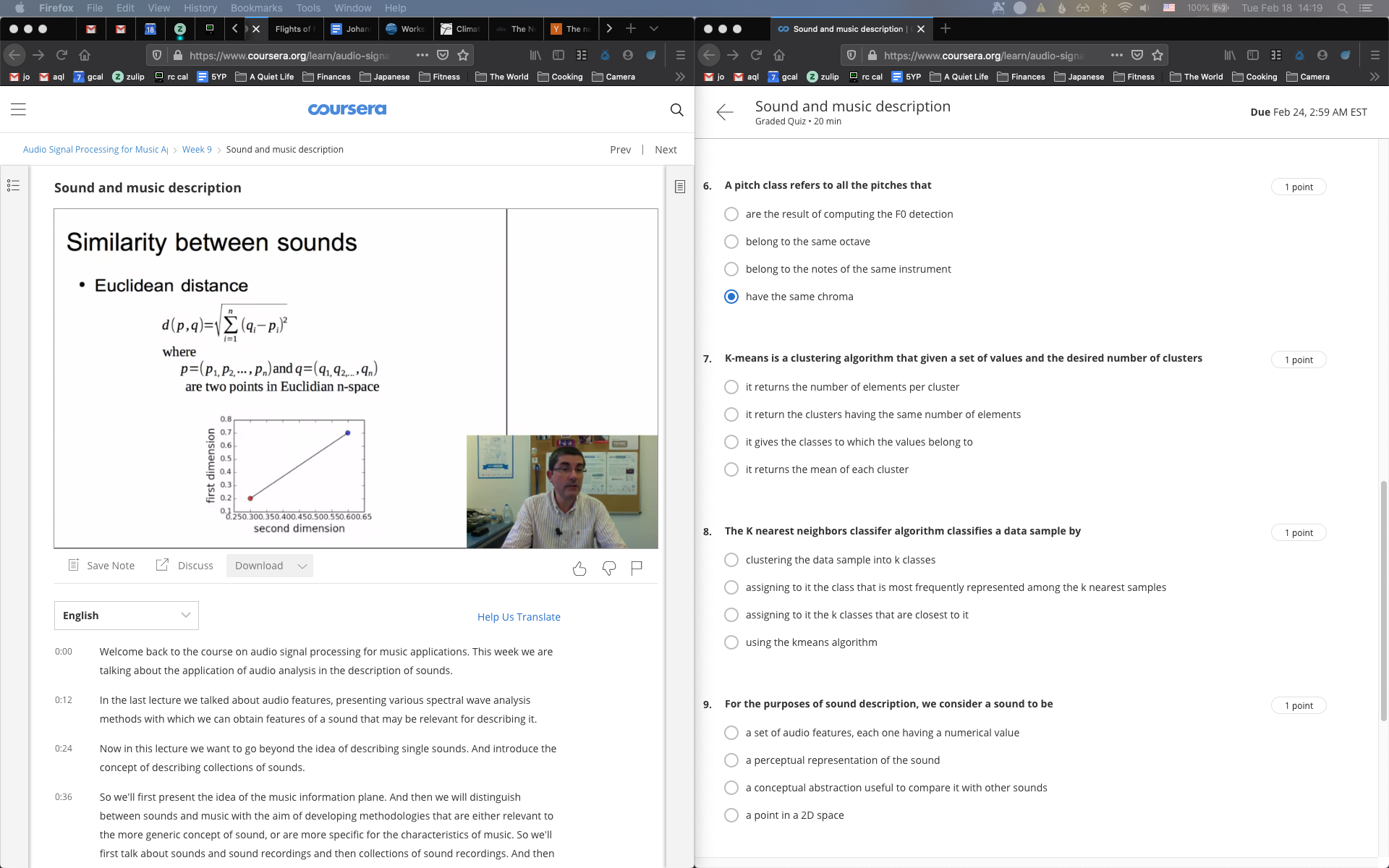
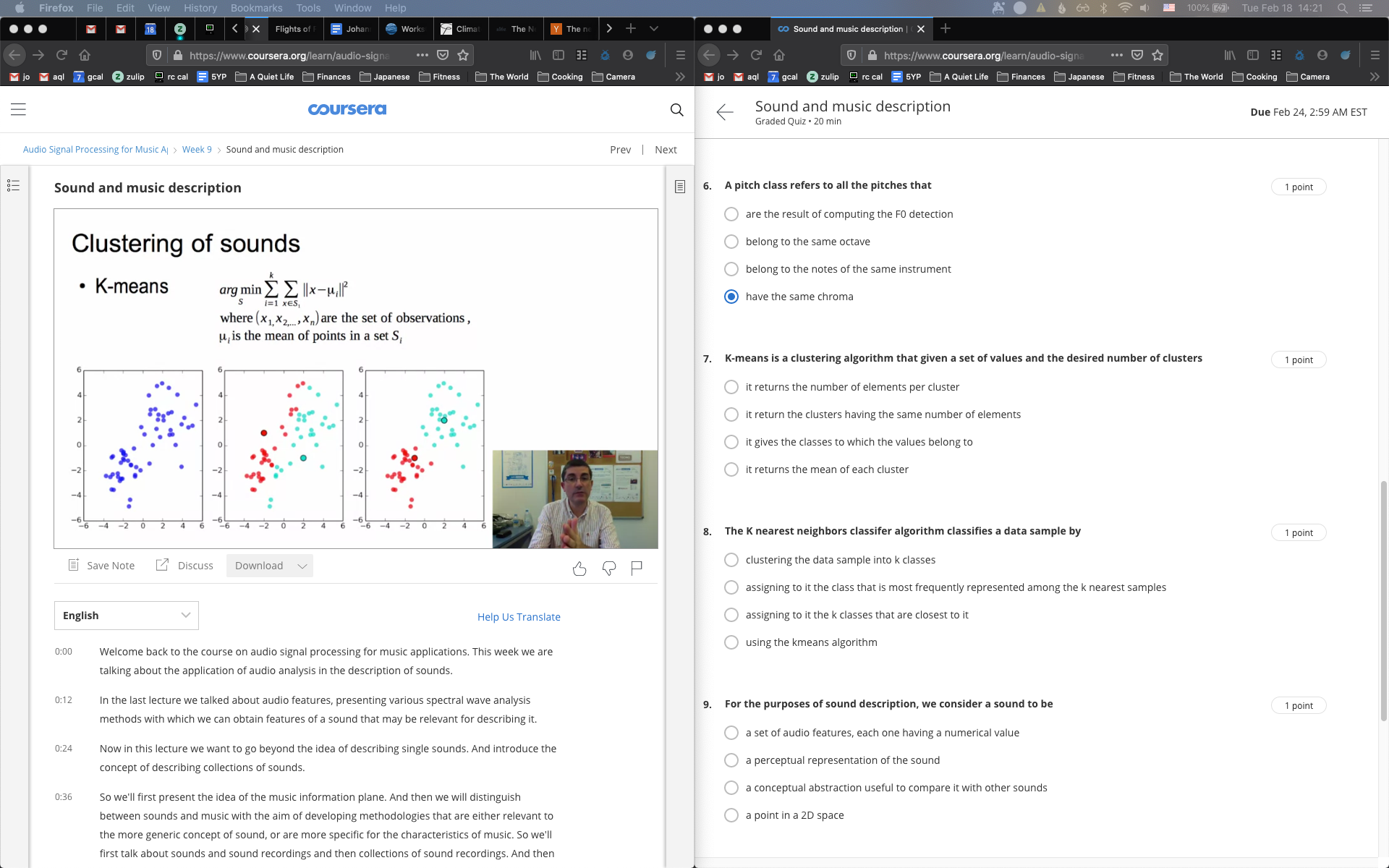
Sound Collections
Sound Similarity
Sound Clustering
The first half of next week should have me in the same headspace, and then starting on Tuesday I'll be back to coding: working on the fastai audio library, training more model examples, and working on my real-time audio classifer mobile app.
Hope to see you out at some of my upcoming events! ✌ 🏿
Today is the end of my sixth week at Recurse Center, and the halfway point of my 12 week batch. Its 9am, and I'm sitting here by myself on the 5th floor, feeling exhausted but in a good way, tired yet full of energy, unsure about how I feel about the week but knowing that I've accomplished a lot and still have an equivalent amount of time left to push myself to do more.
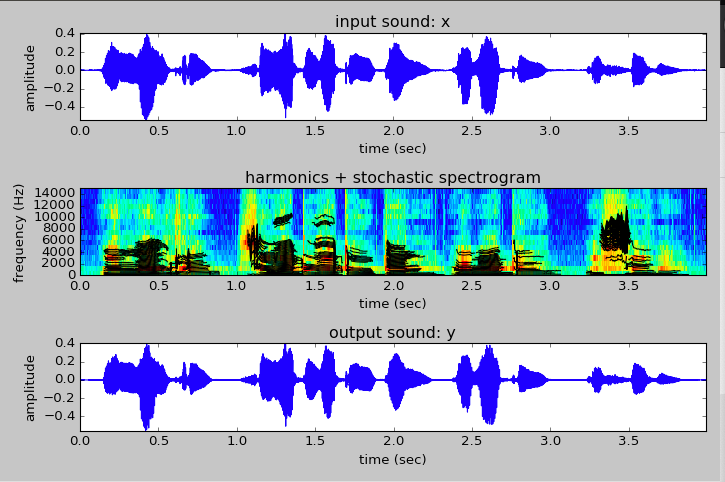
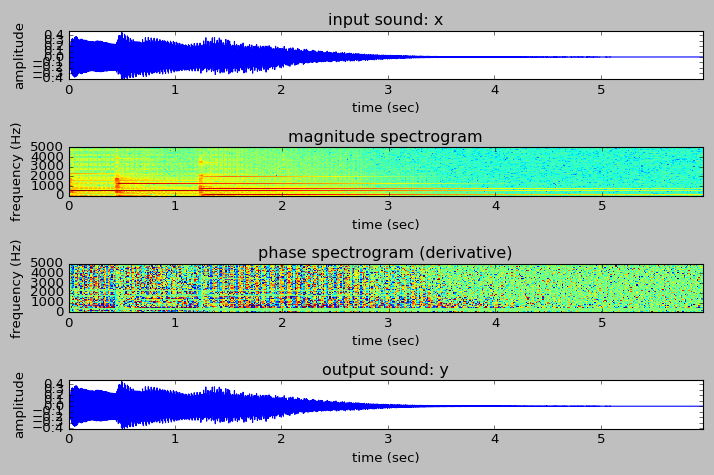
This week I finished week 8 of ASPMA, which was really interesting and was actally the kind of material I was hoping to learn. We learned about sound transformations, and how we could take a lot of the fundamental ideas and models from previous weeks (short-time Fourier transformations and the harmomic plus residual / stochastic model) in order to make some really compelling transforms. Here are some screenshots of some of them.
I'm looking forward to taking some of these techniques with me to Pioneer Works in and seeing how I can incorporate them when generating new soundscapes.
I also finished Part 1 of the fastai Deep Learning course for a second time! It was great getting a second pass at the material, as it really does require multiple viewings because of the density. Something I noted to look into is how to use (W)GANs to create new soundscapes from (environmental/industrial) noise. I think there is a lot of rich material here, especially in thinking about the poetics of taking enviromnetal "noise" and turning it into a more "desirable" state. I'm really excited to now know about some approaches that I can play with at Pioneer Works!
One of my goals for the week was to build out a prototype of a mobile app that shows your camera view, and also lets you record and playback audio. I'm happy that I was able to achieve that goal this week! Using Expo, I was able to get the camera view up and running in no time.
With the help of another Recurser, we were able to take Expo's audio recording example and refactor it to work in my current app.
I'm not sure specifically where to go next with this (maybe making spectrograms on the phone?), but I feel like this was a great first step and gives me confidence in moving forward with this project.
I hit a plateau with my bird sound classifier this week and kind of stalled out on it... I spent most of the week training, and tried running a 20+ hour training job overnight that ended up not completing. Lesson learned: If you can (and I can!) run something in a smaller, incremental number epoch cycles, do that! My sneaking suspicion, after talking with another Recurser, is that the Python process managing my training was doing a poor job managing memory, causing the RAM on Mercer (one of our GPU-enabled cluster computers) to slowly fill overtime and not get released, which in turn caused a swapdisk process on the machine to constantly go back in forth between trying to retrieve memory to and from the hard disk. I'm running my training again with a smaller amount of epochs (10 instead of 30), which I think is much safer and will always be done if I run it over night. I almost went home in defeat but took some time to do some non-coding things and felt better in the end :)
Me going down to visit Mercer to say "You're doing a great job...keep going!!"
So close and yet so far...
I think I hit a point with this project where I should try reaching out for advice on how to move forward, so I'm going to be posting my notebook to the fastai forums to see what others think. Next week I need to get my head out of the weeds, step back and tie it up at this point, in order to have a nice completed version of this project to share for my upcoming Localhost presentation.
I think my goals for next week will be tidying up my bird classifier project and demonstrating it doing inference on recordings from the dataset, and then from recordings of birds found in the Newtown Creek (ideally with my own recordings). All of this should be in the service of preparing for my Localhost talk. I think with that done, I'll be in a better place to try training models on outher audio datasets. I'd ideally like to also find time to pair with others on my mobile app, which is already at a good place. As always, I'll be continuing ASPMA, 6.006 lectures, and now Part 2 of the fastai Deep Learning lectures!
This week felt a bit chaotic, but maybe the good kind? I feel like I had a few small victories, and reached a new plateau from which I can start to look outward and see what I want to accomplish next. A local maxima, if you will.
Over the weekend I attended NEMISIG, a regional conference for music informations/audio ML at Smith College. I feel like I got a lot of good information and contacts through it, and it was a really valuable experience that I'm still unpacking.
My kind of humor, only to be found in a liberal Northeastern small college town
Poster session for the conference
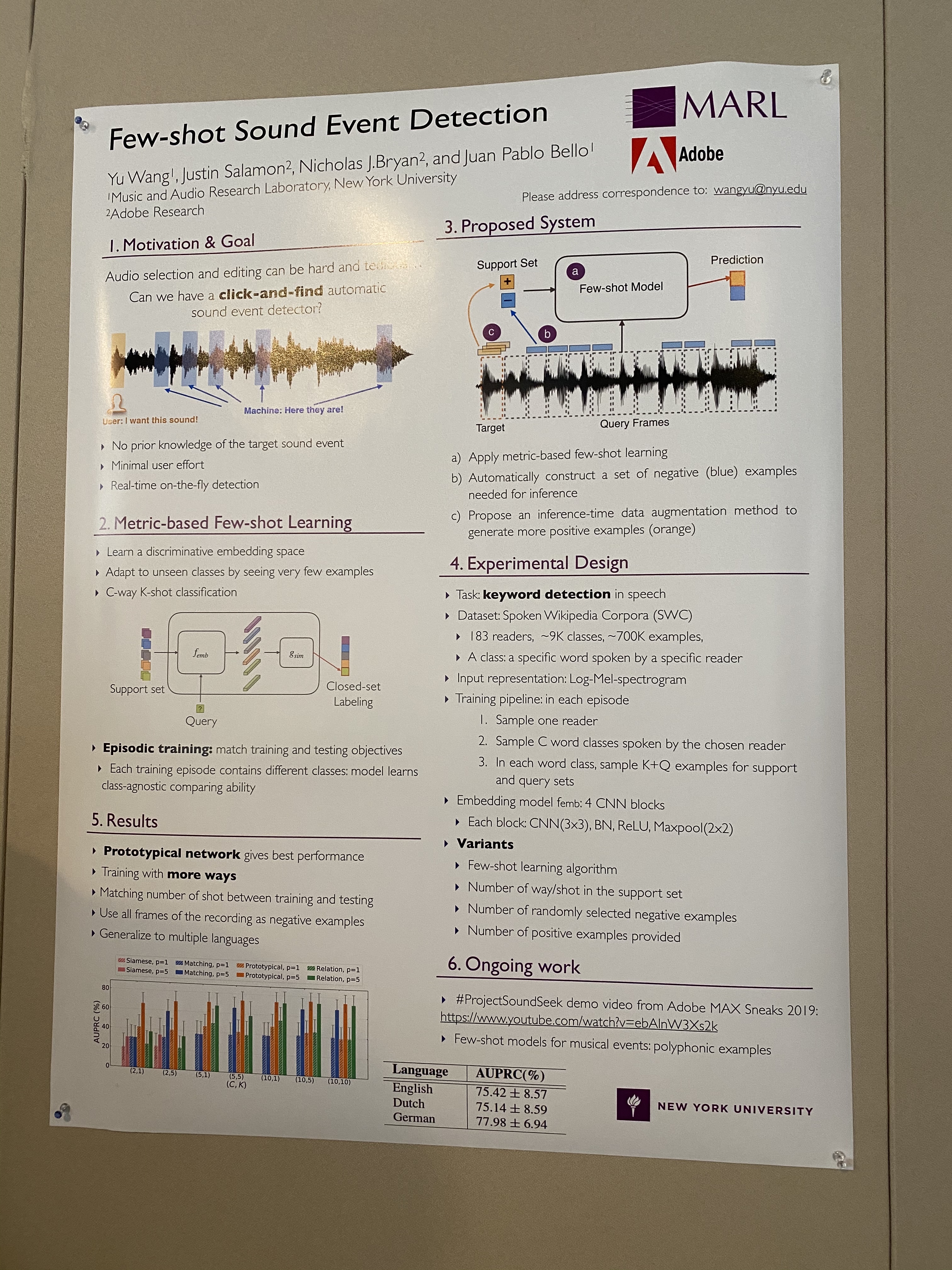
Poster on Few-shot Sound Event Detection
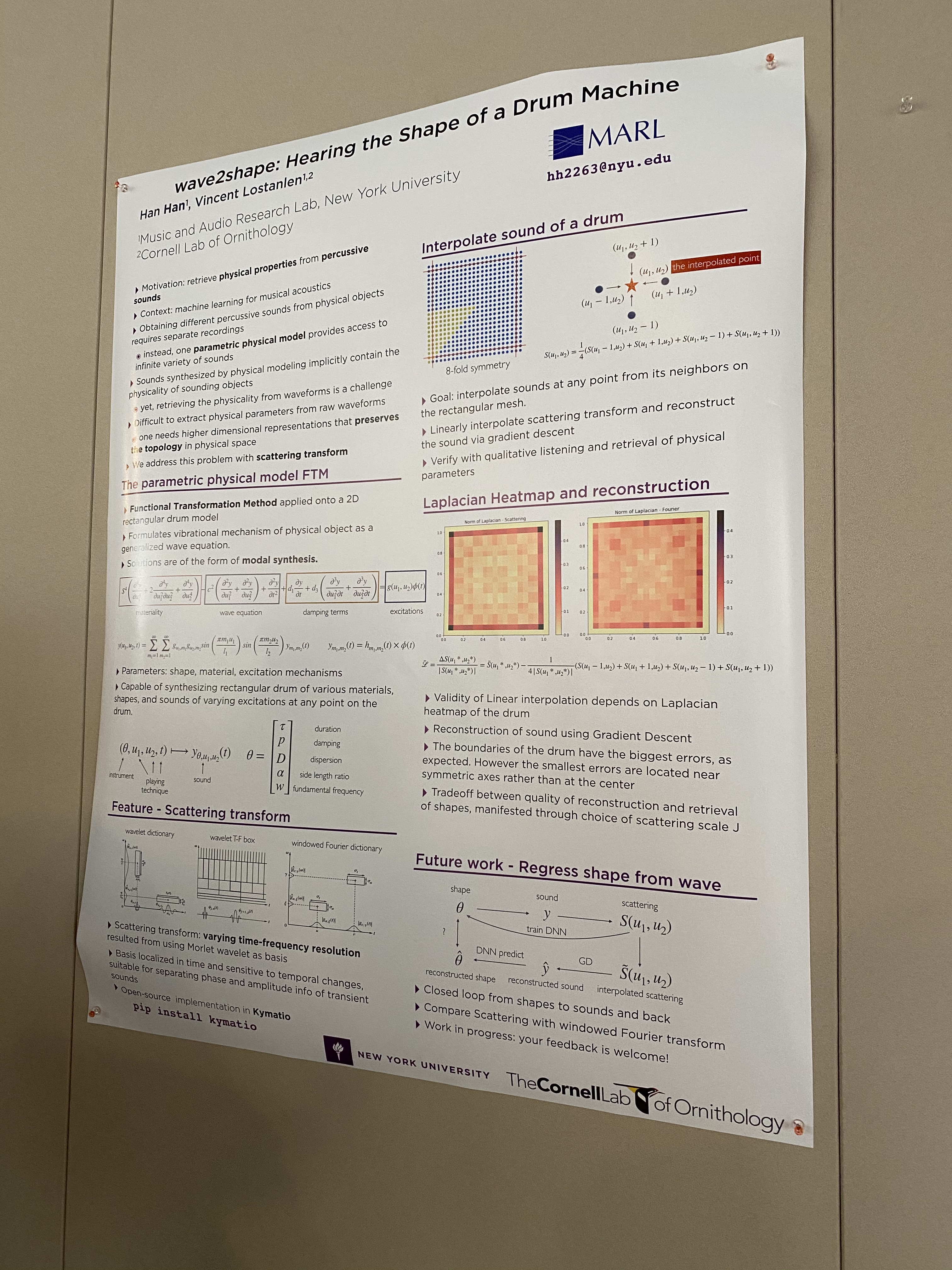
Poster on wave2shave - drum physical modeling using scatter transformations
Vincent Lostanlen giving us a whirlwind crash course into scatter transformations and wavelets
One of my RC conpatriots put me on to Olivier Messiaen's Catalogue d'oiseaux, relevant to my bird sound research
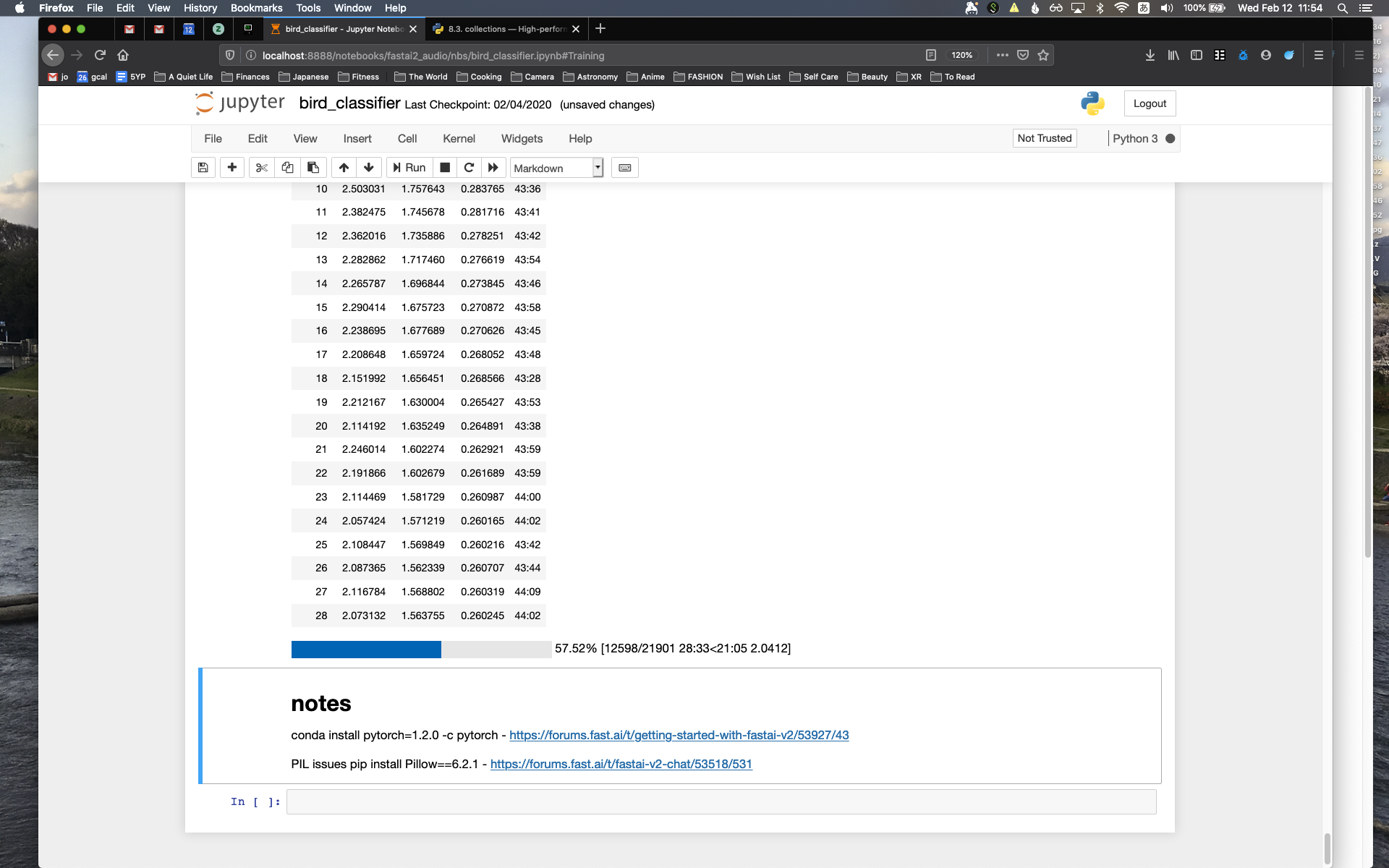
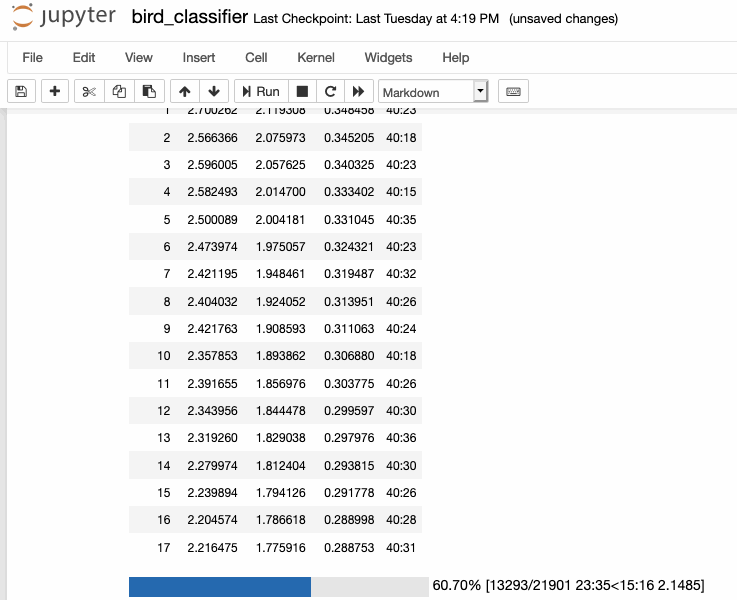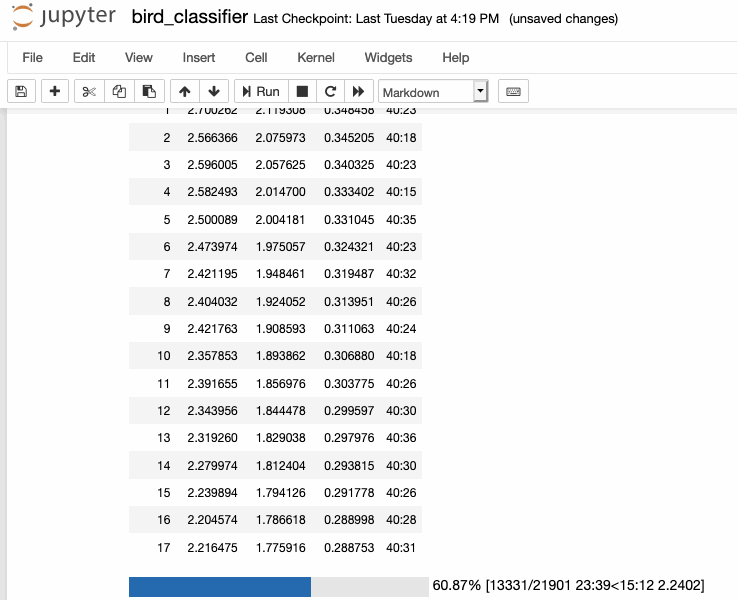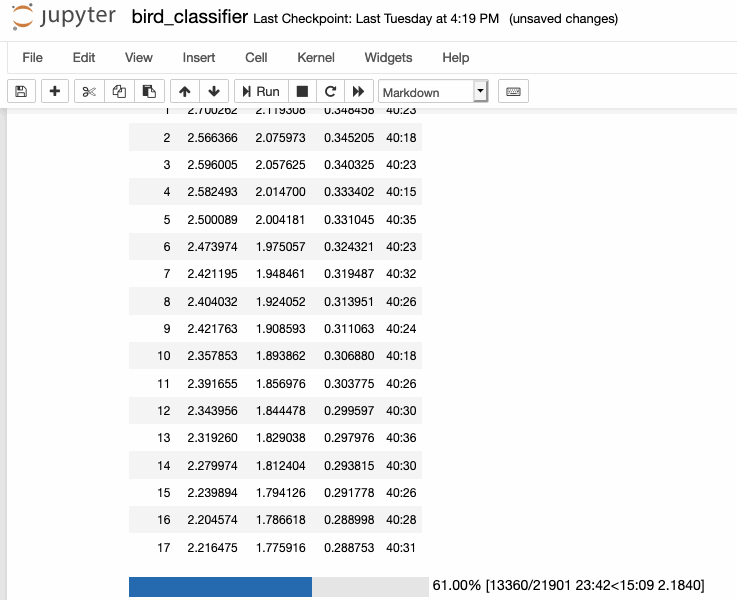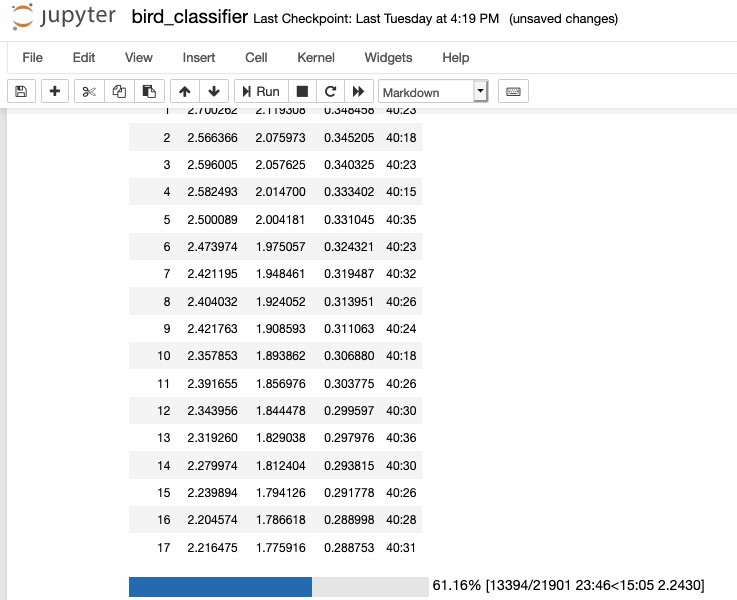
This week I finally got to training my bird sounds! After spending last week creating my spectrograms, I was able to move everything over from our cluster machine with the largest amount of space (broome) to a GPU-enabled machine for training (mercer). Afterwards, I looked at some of the new fastai tutorial notebooks to put together the training pipeline necessary to train with my spectrograms.
As of writing, I was able to train my model down to a <30% error rate, which is really greatcompared to the literature I read before, which was much higher (closer to 50%).
I still don't understand some of the metrics involved in some of evaluations in papers, so I'm going to dedicate sometime to understand them better in order to better understand my own training metrics. For example, the paper written about this dataset, Recognizing Birds from Sound - The 2018 BirdCLEF Baseline System, says thei "best single model achieves a multi-label MLRAP of0.535 on our full local validation set including backgroundspecies after 70 epochs". I'm not really sure how to calculate that and how that even relates to my single-label classification method, so its definitely something to dig into.
I am using transfer learning to train my dataset with a ResNet34 architecture trained on mageNet, which is definitely why I'm getting such good results. After doing some more testing, I should retrain the whole model a bit by unfreezing it, and then train it specifically on recordings of birds from the Newtown Creek. Only then will I have a classifier that will work on those specific species of birds.
Starting next week I want to train another neural network based on the Freesound General-Purpose Audio Tagging Challenge on Kaggle, which uses the FSDKaggle2018 dataset found on Zenodo. In doing all of this, I think its going to be important to figure out a good way to pick out relevant parts of audio signals for training. This goes back to the "eventness" paper I was talking about in my last post, and as I see that weakly labeled data is a perennial problem in audio classification taks, it might end up being an area that I can focus on and try to offer some novel solutions.
All of this work is helping lead me to making my real-time audio classifier mobile app, which I started whiteboarding this week.
Whiteboarding a real-time audio classifier
Next week I want to do some preliminary research and maybe just get something deployed on my phone that shows the camera feed, with it maybe recording and playing back sound just to make sure that works. That would be a really good first step! I want to reach out to MARL at NYU because I know I saw a real-time classification demo they made with their SONYC project. It would be nice to get some insights from them on how to tackle this problem, and what challenges I might face along the way.
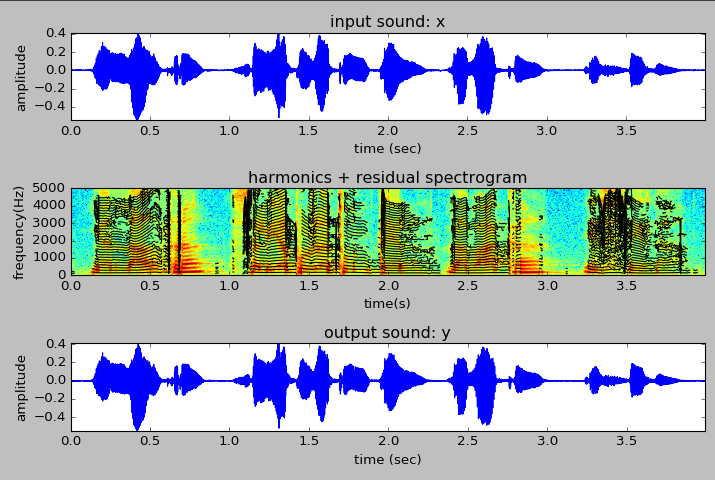
I also finished up Week 7 of ASPMA, where we looked at different models for analyzing and reconstructing residual parts of a signal not captured by the sinusoid/harmonic model, speficially with a stochastic model. It was pretty interesting and it has been nice seeing how all of these transformations and models are coming together to allow us to do some pretty sophistaced stuff.
Harmonic plus residual analysis
Harmonic plus stochastic analysis
Doing some short-time Fourier transform analysis on a vibraphone sample
I had some breakthroughs with algorithm questons, specially around binary trees. For the Algorithm Study Group, I presented a way to solve the question of finding the maximum depth of a binary tree in a way that could be used as a template for solving other binary tree problems. It felt nice to feel like I was making some progress around the topic!
My 9am morning routine, watching MIT 6.006 lectures
Me whiteboarding out a solution to finding the maximum depth of a binary tree
Me presenting my solution to the Algorithms Study Group
This week at RC I focused on preparing by bird sound dataset for traning next week. I decided to go with the LifeCLEF 2017 dataset, which "contains 36,496 recordings covering 1500 species of central and south America (the largest bioacoustic dataset in the literature)". Much of my week was spend reimplementing a spectrogram generation pipeline from the BirdCLEF baseline system, which used this same dataset.
The pipeline goes through all the 1500 classes of bird species, and for each recording, the piplelne creates one second spectrograms across the entire recording (with a 0.25 second overlap between each generated spectrogram). From these spectrograms, a signal-to-noise ratio is produced to determine whether or not the spectrogram contains a meaningful signal that we use to determine if it contains a bird vocalization of that species.
If the signal-to-noise ratio is above a certain threshold, we save that spectrogram in a folder for that bird species. If not, we save that noise-y spectrogram to be usedlater for generalizing during training.
This whole process takes an estimated six hours to run, and it results in about 50,000+ spectrograms across the 1500 classes of bird species.
My intuitive feeling about this process is that it is a bit heavy-handed, suseptible to inaccuracy, and not very efficient. However, I can understand the approach and ultimately it does get the job done. I do think this paper on Eventness (a concept for audio event detection that used the idea of "objectness" from computer vision and applies that to detecting audio events in spectrograms) proposes a more nuanced way to pull out meaningful sonic "events" in a recording. It might be something worth incorporating in another pass on this system.
I'm happy I achieved my goal for the week of generating the spectrograms from the recordings! I have been full of doubts though of how this fits into my larger goals. I think this week I fofocused on the "trees" and not the "forest", so to speak, and maybe what I'm feeling is getting a bit lost in the forest. With most of the data processing out of the way, I'm xcited to pull out a bit and think more about the context of what I'm working on and how it fits into my overall goals.
For instance, generating all of these spectrograms with this pipeline has moved me way from contributing to the fastai audio library. If I had wanted to keep down that path, I would have had to really work to not cut up the spectrograms in the way that I did, and instead come up with a way to generate the onset/offset times of the bird vocalizations from each recording and do the on-the-fly spectrogram generation with the built-in fasai audio library tools. I think that doing the actual learning task is what I want to be focusing on though, so maybe that makes it ok that I reimplemented another way of doing it, because it serves my end goal of diving deeper into the learning part of classification (it is something I would love to go back and dig deeper into though).
With that observation in mind, I think that focusing on training a neural network on these bird vocalization spectrograms next week will get me back into contributing to the library and focusing on the things I want to learn. I don't think this particular bird classification project will lead me to fixing the batch display issue, for example. I think that's okay, and maybe it will just be something I circle back to later on when trying to do other classification tasks with the other datasets I'm interested in.
I think going back to my larger goals at RC, I want to create a real-time sound classification application that can be used to classify different kinds of sounds. I've made a model for environmental sounds, and now I'm tackling bird vocalizations. I want to look at other environmental sound datasets, and if I have the time, I want to do speech as well. I think having this app as a "wrapper" application that lets you do, in general, real-time classification with any model you import will give me the room to d training on many different datasets, giving me more opportunities to dig into fastai v2, the audio library, convolutional neural networks, real-time on-device machine learning, short-time Fourier transforms, and classification in general.
So for now, my goals are to finish up the bird classification system, get it on device, and then make more models to get better at using deep learning for sound classification and understanding what it takse to do real-time on device machine learning.
Hello again. Its been really nice taking the time on Fridays to try to write and collect my thoughts on what I've been doing over the course of the week, looking back on the previous weeks, and looking forward into the future.
At the end of last week, I spent some time trying to diagram, to my understanding, the world of audio ML. Here's a photo of what I whiteboarded:
What I started to realize is that the field of audio ML has two distinct "sides": analysis and synthesis. This shouldn't be too surpiring to me. In my Audio Signal Processing class, we're always talking about analysis first, and then synthesis (which is usually the inverse of the analysis process).
This lead me to thinking that what how I should spend my time at RC. Maybe I should spend my first six weeks deeply working on analysis, which in this case would be classification tasks. Then, I could spend my last six weeks looking at synthesis, which would be the task of genrating sounds. This was what I was thinking about doing before coming to RC, and this approach seemed like a good way to see the entire field of audio ML.
I was worried though. Would I actually come out with something subtantial if I split my time like this? My larger goal at RC was to become a dramatically better programmer, and I began to think that maybe becoming more of an expert at one side of the coin would actually prove to be a better use of my time here.
The answer I came to was also driven by the fact that I would be a resident at Pioneer Works right after my time at RC, so I would be spending an addtional 12 weeks somewhere else where I could be more "creative" and "artistic" in my approach. So, that lead me to decide (for now) that I would dedicate the rest of my time at RC fully and deeply understanding the analysis side of audio ML, and build out a tool kit for real-time audio classification that I could use in the field. Yay!
With that in mind, I'm continuing my investigation into bird sound classification, with the intention of making a real-time audio classification app that lets you identify birds in the field, along with other environmental sounds (which would end up being an upgrade to my Whisp app), and speech as well. I don't necessarly have to get to all of these things at RC, but I can build out the scaffolding/framework to do this, and use bird sounds as my first, deeply investigated dataset. I think I will also have the time to fold in environmental sounds as well, as its something I've done before, and maybe even sneak in speech as a stretch goal.
All of this is being facilitated with my involvement with fastai's audio library. I'm proud to say that my first pull request was merged into the library this week! This makes for my first open source contribution :D
I had a lot of great conversations with people in the audio ML space this week, including Yotam Mann and Vincent Lostanlen. Both have been super supportive in my work and have made themselves available to help out where they can. In particular, Vincent pointed me to a lot of great research around bird sound classification, including BirdNet. I wasn't able to find their dataset, but it lead me to the BirdCLEF dataset. Vincent said it was weakly labeled, with no onset/offset times for the bird sounds, so it might require a lot of work to get going. We shall see!
Otherwise, this week was also good for my Audio Signal Processing class. We learned about the Sinusoid model and how to do things like spectral peak finding, sine tracking, and additive synthesis.
In algorithms, a lot of time this week was spent on trees, including binary trees, binary search trees, and self-balancing trees like AVL trees. In the Algorithms Study Group we also spend a lot of time looking at Floyd's cycle finding algorithm, quicksort, and graph traversal algorithms like depth-first search, breadth-first search, and Dijkstra's shortest path finding algorithm.
Hello! This week I really felt like I made a lot of progress towards my goals. A lot of things came together in a really great way, and I can start to see how my overall approach to RC and what I'm studying is informing each other and interleaving in ways that I wanted it to.
This week I started by getting a lot of video lectures out of the way on Sunday, including the week 4 of fastai's deep learning course and ASPMA. That really set me up well to focus on programming for most of the week, instead of burning most of my time with lectures and fueling my anxiety that I'm not programming/making enough.
I also decided this week to try not to context switch as much - for now, I'm trying to still spend the mornings working on algorithms, but now I'll alternate days where I focus one day on ASPMA/audio signal processing and the other day on audio ML/fastai. I think it worked out really well this week, and made me feel less anxious to rush through something so I could switch to another related but contextually different tasks. So for this week I did ASPMA work on Monday and Wednesday, and audo ML work on Tuesday and Thursday. I found it successful, so I'm going to try it again next week!
This week I feel like I made a lot of progress in the audio ML front, combining some of the stuff I've been learning about in the ASPMA course into the work I've been doing with fastai's new audio library. In the ASPMA course, we learned about short-time Fourier transform and how its used to generate spectrograms. I was able to use some of that knowledge to try to make a real-time spectrogram generator from the microphone. It didn't turn out super well, and its something I want to master, so I think I'll take another crack at it next week.
Earlier in the week, I met with Marko Stamenovic, an RC alum who works professionally on audio ML at Bose. We had an amazing conversation about audio ML, some of the current topics in the field, areas to check out related to my interests, and what it would be like to work professionally in that field.
We talked about a lot of topics that I need to go back and check out, including:
ML Signal Processing
Neural audio synthesis
The MARL community out of NYU (Brian McFee, Juan Pablo, Keunwoo Choi)
The Music Hackathon community
For audio generation, Marko pointed me to:
- WaveNet (DeepMind)
- FFT Net (Adobe, Justin Saloman)
- LPCNet (Mozilla)
He suggested first trying to genrate sine waves, then speech, then field recordings with these architectures.
Marko also told me to really focus on the STFT as its a fundamental algorithm in audio ML. He also mentioned that being able to do deployed real-time audo ML on the phone is very in-demand so that might be something I try to refocus on while at RC.
This week I was also able to finish my PR on fastai's audio library. The task at hand was creating a test to make sure spectrograms generated with the library always returned right-side up. I was able to use some of the skills I learned in the ASPMA class, specifically around generating an audio signal, in order to create a test case to create a simple 5hz signal, generate a spectrogram from that, and test to make sure the highest energy bin in that specgrogram was at the bottom. This was such a great moment where everything felt like it came together, and I only imagine that this will happen more and more :)
Finally, I did more MIT 6.006 lectures on algorithms. This week was sorting, including insertion sort, merge sort and heap sort. I particularly love heap sort! I also gave a small presentation on merge sort at RC as part of our Algorithms Study Group, which forced me to really dig into merge sort and understand how it works, including writing out its recursion tree. I love forcing myself into situations that make it guarenteed that I'll have to really focus and deeply understand something so that I can present it to others. I hope to do it more in the future.
For now, I think everything is moving well. I do want to realign what I'm working towards, and try to keep the bigger goals in mind of making something that generates sound. I do think though that the listening part of this is just as important, so I want to think about how to combine the two, because I do think they are both two sides of the same coin. I'll spend a bit more time thinking about that today and I'll hopefully have some idea forward before setting my goals for next week.
Hello! If you are reading this, welcome! This is my attempt to be a better (technical) writer, starting with writing about my programming life at the Recurse Center. For more about me, please visit my personal website. For a quick intro, I make installations, performances, and sculptures that let you explore the world through your ears. I surface the vibratory histories of past interactions inscribed in material and embedded in space, peeling back sonic layers to reveal hidden memories and untold stories. I share my tools and techniques with others through listening tours, workshops, and open source hardware/software. During my time at RC, I want to dive deep into the world of machine listening, computational audio, and programamtic sound. To do that, I'm splitting my time, 2/3s of which will be spent on audio ML and audio signal processing. The other 1/3 of my time will be spent on getting a better foundation on computer science, algorithms, and data structures. In the following post, I'll write about my experience with those areas, and pepper in some observations along the way that I've had since being here!
On the audio ML side of things, this week I dove into fastai's new version 2 of their library, specifically so I could start working on their new audio extension! I'm really excited to contirbute to this extension, as this will be the first time I've really contributed to open source. The current team seems incredibly nice and smart, so I'm really looking forward to working with them. The first thing I did was get version 2 of fastai and fastcore setup on my Paperspace machine, but then I realized that I could/should get it set up on RC's Heap cluster! This took a bit to get working, but it was pretty smooth to get everything setup, so now I feel ready to start working with it. My first project idea was to build a bird classifier, using examples of birds found around the Newtown Creek. I was able to put together a test dataset from recordings I downloaded on https://www.xeno-canto.org/. I did want to start training this week, but I think that's going to have to happen next week. This week I also finished up to week 3 of the fastai DL lectures, so that was good progress. Next week I'll tackle week 4 and use the rest of the week to actually code something.
On the audio signal processing side of things, I was able to finish week 3 of the Audio Signal Processing for Musical Applications course on Coursera, which I've really been enjoying. Week 1 and 2's homework assignments were pretty easy and straightforward, but this week's homework assignment was way more difficult! I didn't expect it to take as much time as it did, and I did have to cut some corners at the end and look at someone else's example to finish it. It wasn't the most ideal situation, and I now know going into next week to anticipate needing to spend more time with the assignments.
Finally, on the algos side, I finished Lectures 1 and 2 of Introduction to Algorithms 6.006 from MIT Open Courseware. I tried a couple of LeetCode questions related to those lectures as well. I need to find a way to make sure I actually code things related to that course, instead of just simply watching the videos. My approach has been 1) Watch a video 2) Do a couple of problems related to that, all before lunch. I think if I can get into a good flow for this, I'll be doing just fine.
Over the course of my first week, I've already had my ups and downs. One thing has been being overambitious in what I can get done in a day. I'm ready spending 9am-7pm at RC, and I still have the feeling that I can't get everything done. I'm going to have to be ok with not getting everything done that I've set out to do each day.
I had a nice check-in with one of the faculty members about algo studying and project management. Two takeaways were: 1) Don't spend all your time at RC griding on algorithm studying/cramming videos. Do some, but don't spend the entire day doing it. And 2) Once you feel like you know enough of what you need to get started on a project, start! Let the project drive what you need to learn.
One of the things I think I should start doing is create a list of goals for the week on Sunday night, and then let that drive what I should be focusing on for the week, making sure I've planned out enough time and space during the week to realistically make those goals happen, knowing that I want to leave space for serendipity while at RC.
Going forward with RC, I made a list of projects I want to work on. I'm categorizing them as "Small/Known" (as in I already know how to do them or have an understanding of a clear path as to how to make them real, and "Big/Ambitious", as in I'm not exactly quite sure where to start and they will be take a longer time to do.
For now that list looks like:
Small / Known
NCA / Newtown Creek Bird Classifier
Freesound multilabel classifier
Shubert's tone generator
Big / Ambitious
Voice recognition for security
Sonic generator with GANs
For next week, I want to:
Learn:
Week 4 of fastai
Week 4 of ASPMA
Lecture 3 and 4 of MIT 6.006
Do:
Make bird classifier
Make Shepard tone sound generator
More LeetCode problems