
Week 5: A Local Maxima
Published on 02.07.2020 in [rc]
This week felt a bit chaotic, but maybe the good kind? I feel like I had a few small victories, and reached a new plateau from which I can start to look outward and see what I want to accomplish next. A local maxima, if you will.
Over the weekend I attended NEMISIG, a regional conference for music informations/audio ML at Smith College. I feel like I got a lot of good information and contacts through it, and it was a really valuable experience that I'm still unpacking.

My kind of humor, only to be found in a liberal Northeastern small college town

Poster session for the conference
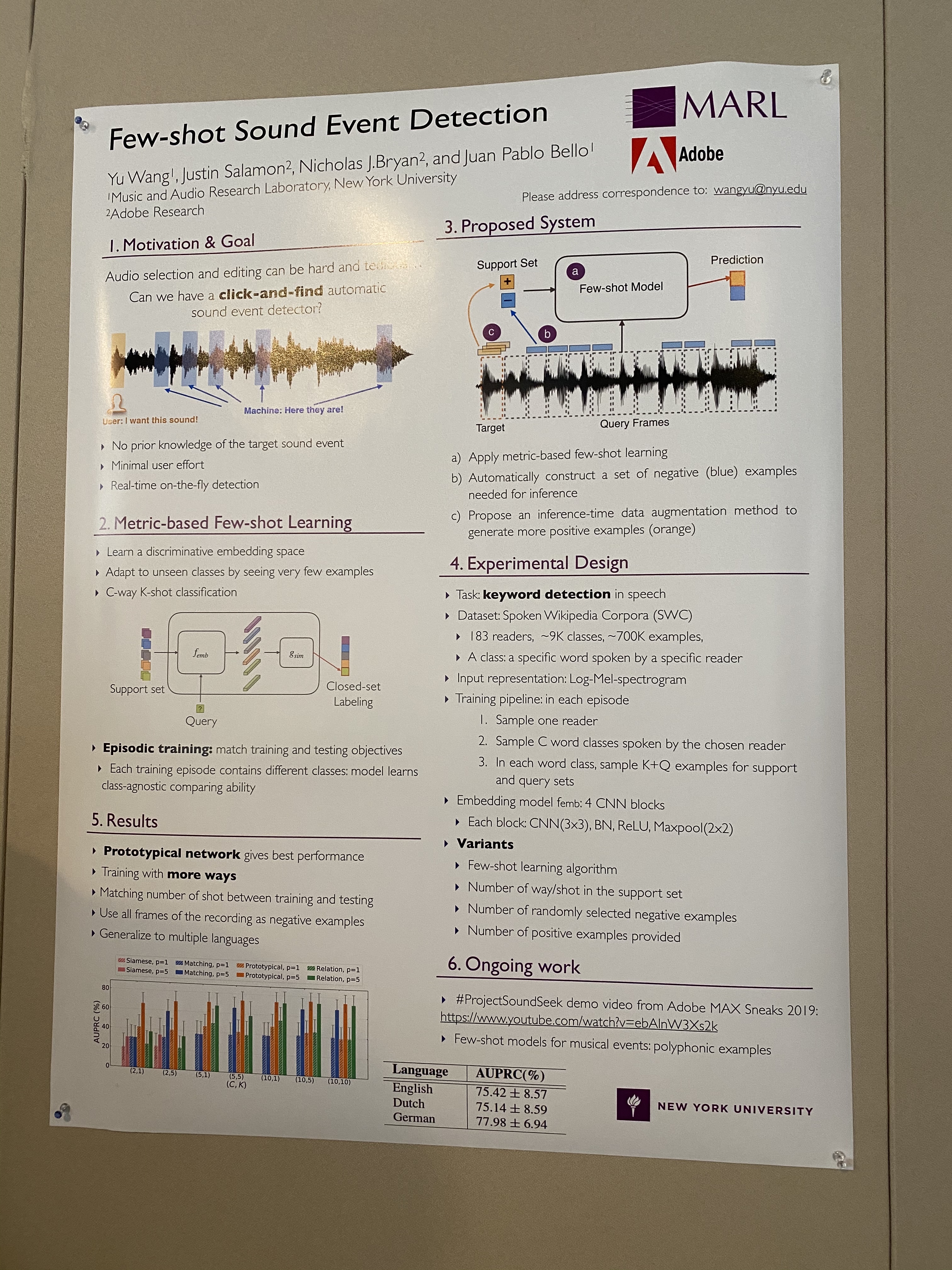
Poster on Few-shot Sound Event Detection
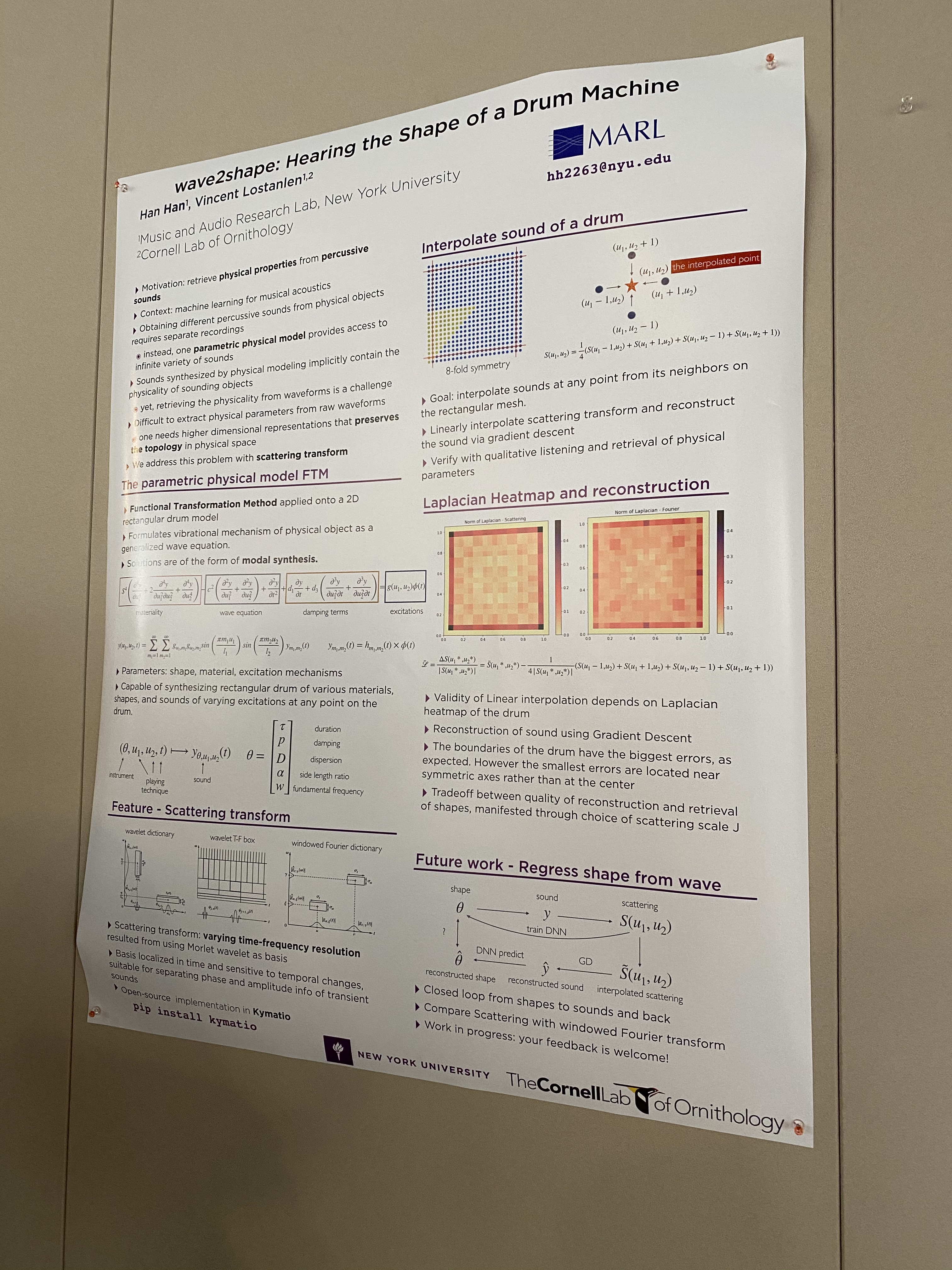
Poster on wave2shave - drum physical modeling using scatter transformations

Vincent Lostanlen giving us a whirlwind crash course into scatter transformations and wavelets
One of my RC conpatriots put me on to Olivier Messiaen's Catalogue d'oiseaux, relevant to my bird sound research
This week I finally got to training my bird sounds! After spending last week creating my spectrograms, I was able to move everything over from our cluster machine with the largest amount of space (broome) to a GPU-enabled machine for training (mercer). Afterwards, I looked at some of the new fastai tutorial notebooks to put together the training pipeline necessary to train with my spectrograms.
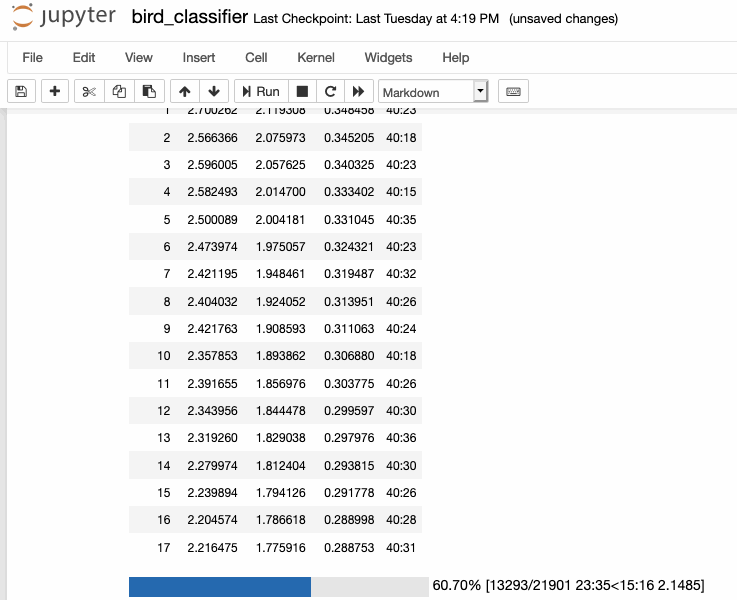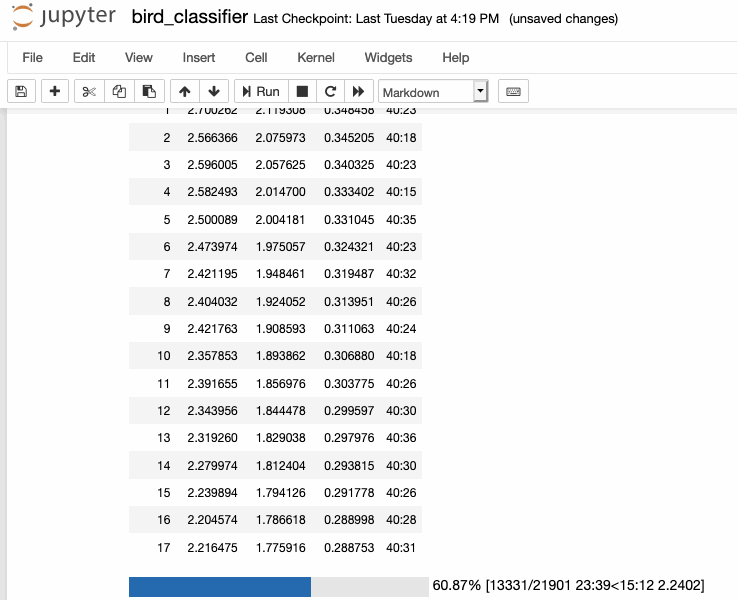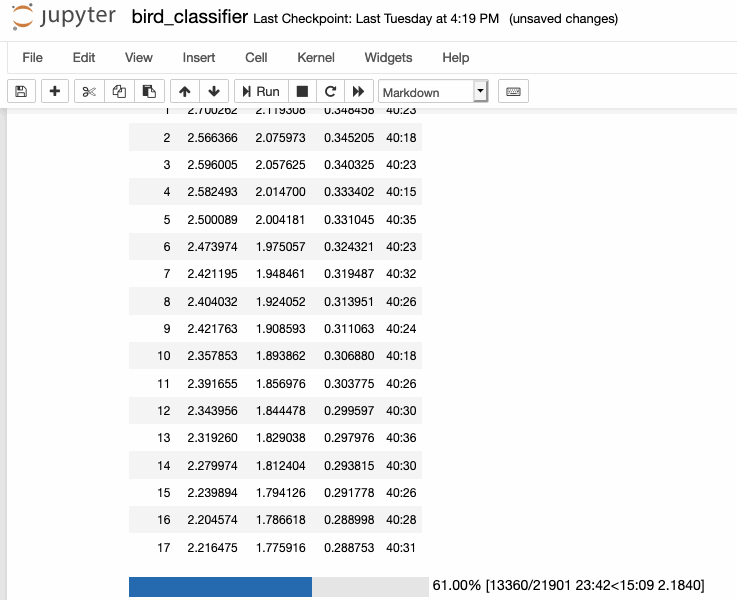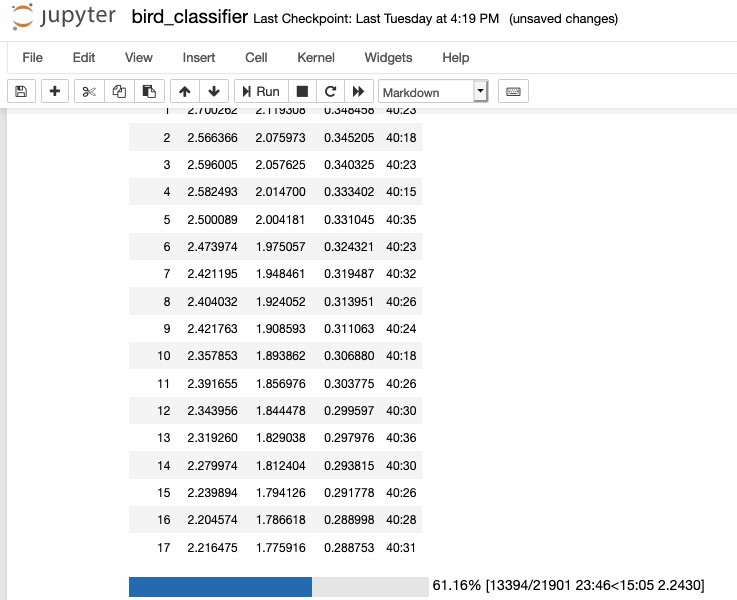
As of writing, I was able to train my model down to a <30% error rate, which is really greatcompared to the literature I read before, which was much higher (closer to 50%).
I still don't understand some of the metrics involved in some of evaluations in papers, so I'm going to dedicate sometime to understand them better in order to better understand my own training metrics. For example, the paper written about this dataset, Recognizing Birds from Sound - The 2018 BirdCLEF Baseline System, says thei "best single model achieves a multi-label MLRAP of0.535 on our full local validation set including backgroundspecies after 70 epochs". I'm not really sure how to calculate that and how that even relates to my single-label classification method, so its definitely something to dig into.
I am using transfer learning to train my dataset with a ResNet34 architecture trained on mageNet, which is definitely why I'm getting such good results. After doing some more testing, I should retrain the whole model a bit by unfreezing it, and then train it specifically on recordings of birds from the Newtown Creek. Only then will I have a classifier that will work on those specific species of birds.
Starting next week I want to train another neural network based on the Freesound General-Purpose Audio Tagging Challenge on Kaggle, which uses the FSDKaggle2018 dataset found on Zenodo. In doing all of this, I think its going to be important to figure out a good way to pick out relevant parts of audio signals for training. This goes back to the "eventness" paper I was talking about in my last post, and as I see that weakly labeled data is a perennial problem in audio classification taks, it might end up being an area that I can focus on and try to offer some novel solutions.
All of this work is helping lead me to making my real-time audio classifier mobile app, which I started whiteboarding this week.

Whiteboarding a real-time audio classifier
Next week I want to do some preliminary research and maybe just get something deployed on my phone that shows the camera feed, with it maybe recording and playing back sound just to make sure that works. That would be a really good first step! I want to reach out to MARL at NYU because I know I saw a real-time classification demo they made with their SONYC project. It would be nice to get some insights from them on how to tackle this problem, and what challenges I might face along the way.
I also finished up Week 7 of ASPMA, where we looked at different models for analyzing and reconstructing residual parts of a signal not captured by the sinusoid/harmonic model, speficially with a stochastic model. It was pretty interesting and it has been nice seeing how all of these transformations and models are coming together to allow us to do some pretty sophistaced stuff.
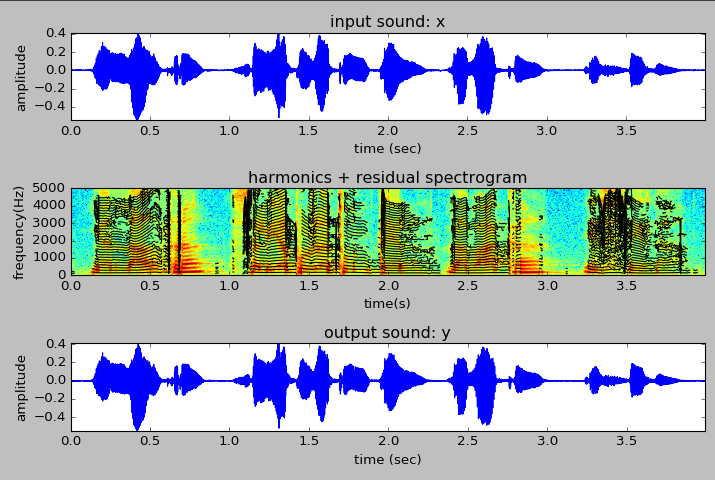
Harmonic plus residual analysis
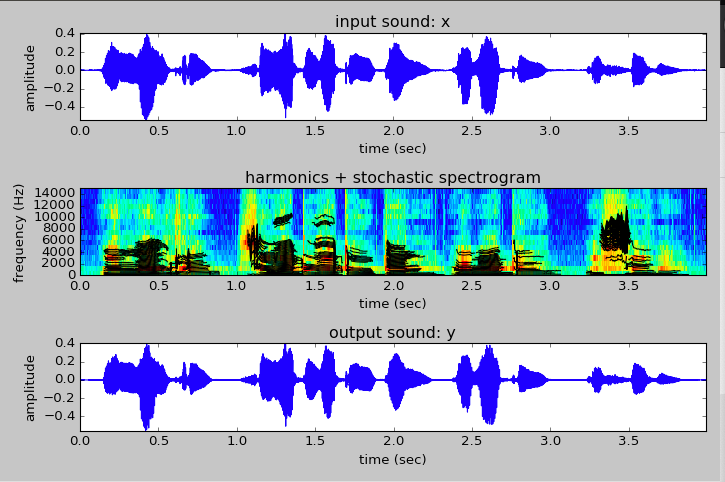
Harmonic plus stochastic analysis
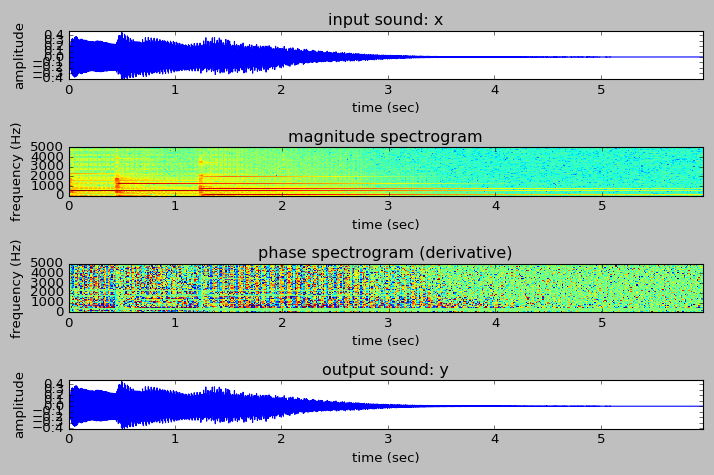
Doing some short-time Fourier transform analysis on a vibraphone sample
I had some breakthroughs with algorithm questons, specially around binary trees. For the Algorithm Study Group, I presented a way to solve the question of finding the maximum depth of a binary tree in a way that could be used as a template for solving other binary tree problems. It felt nice to feel like I was making some progress around the topic!
My 9am morning routine, watching MIT 6.006 lectures

Me whiteboarding out a solution to finding the maximum depth of a binary tree

Me presenting my solution to the Algorithms Study Group